The Gap of Judgement: The Missing...
The Gap of Judgement: The Missing Piece for Enterprise AI Transformation
Source: LLM Watch | Pascal Biese | March 6, 2026
Main Thesis
Despite decades of automation investment, enterprises remain stuck at a productivity plateau because traditional deterministic automation (RPA, ERP) cannot handle ambiguous, unstructured, exception-laden work. LLM-powered agentic AI can finally close this ‘Gap of Judgement’ — but the binding constraint is no longer capability, it is governance and architectural control.
Key Findings
The Automation Plateau
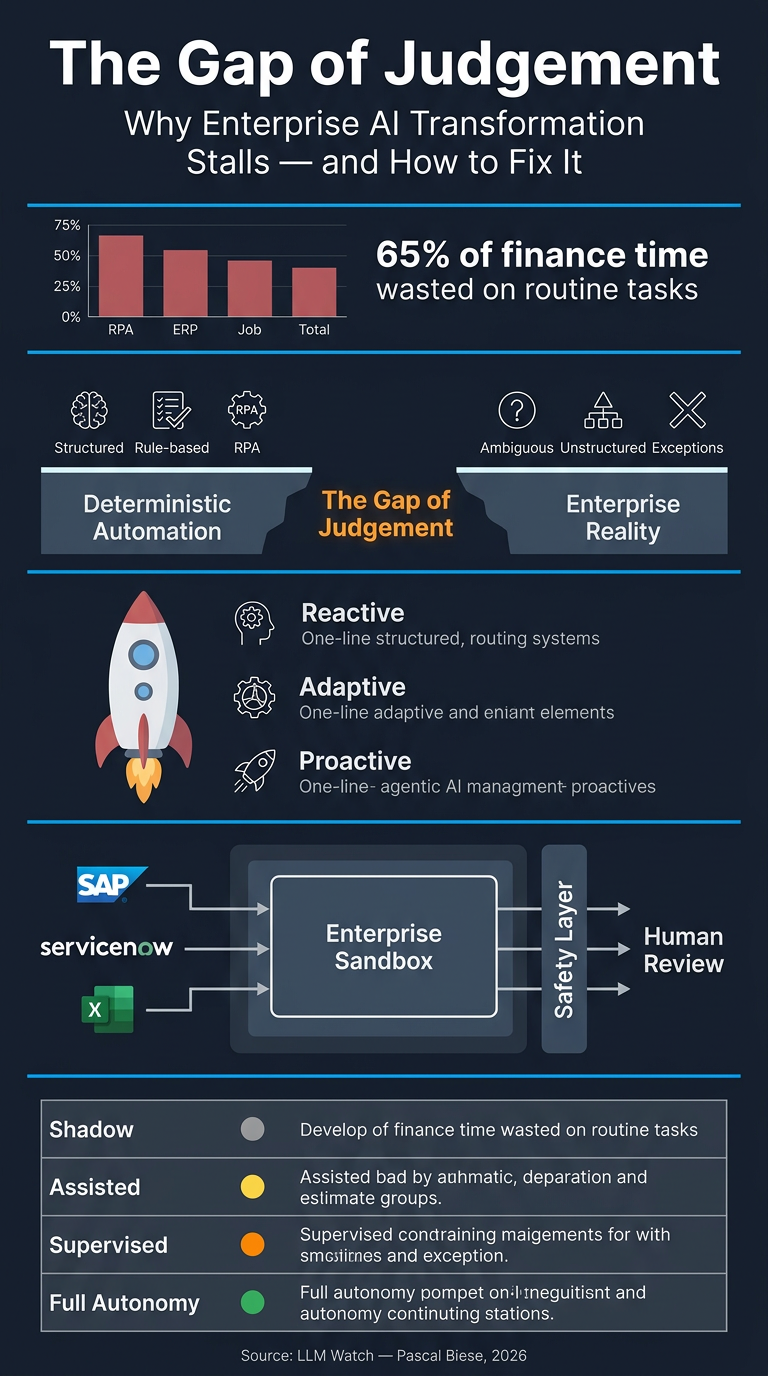
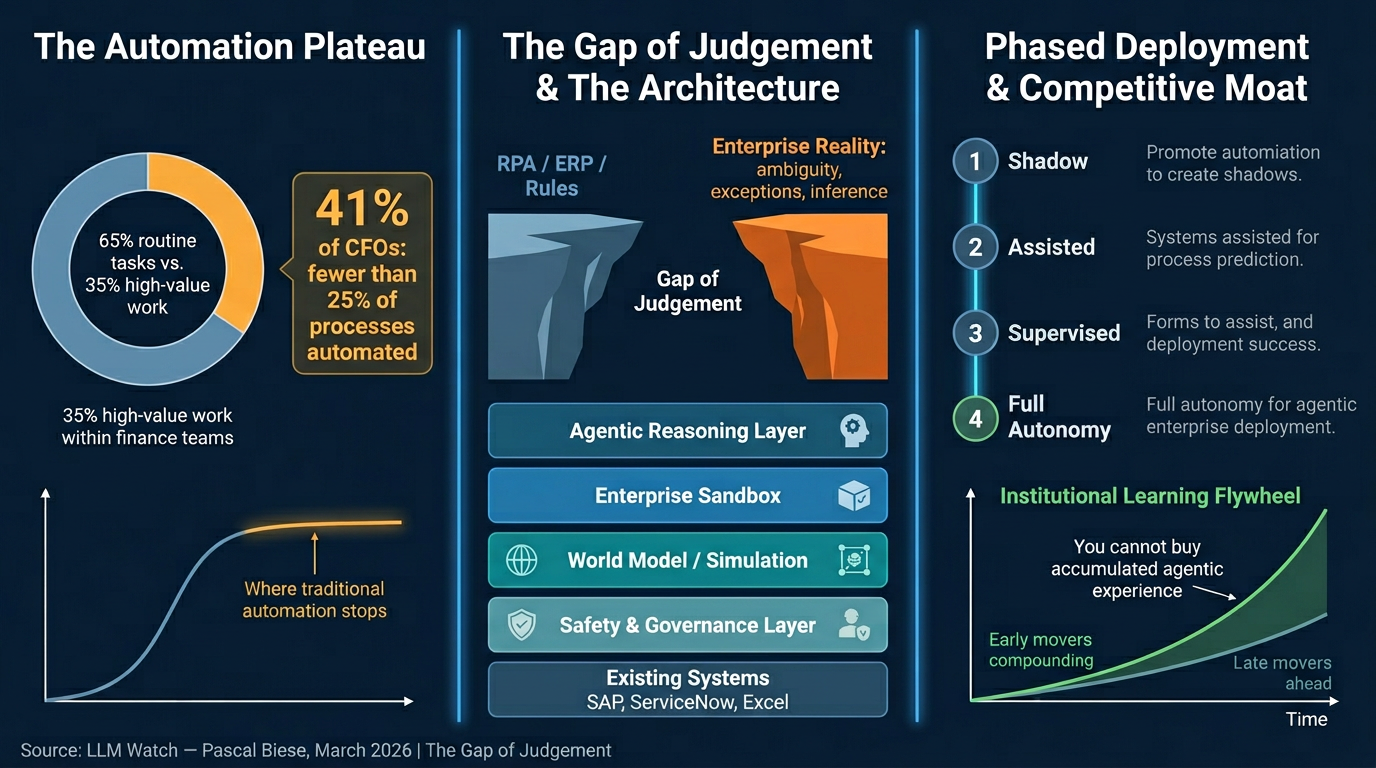
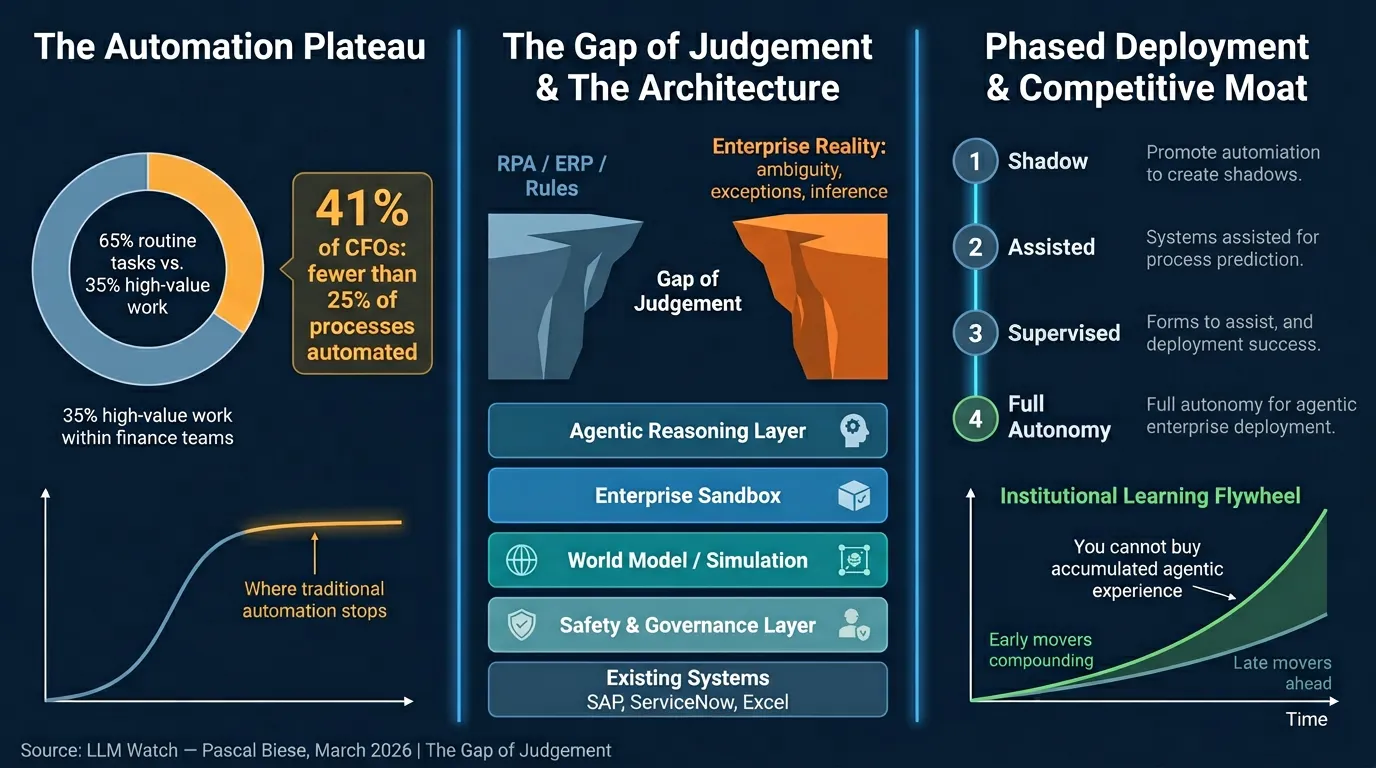
- Only 35% of finance professionals’ time goes to high-value insight work; 65% is consumed by routine data collection and validation (NetSuite)
- 98% of finance leaders invested in automation in the prior 12 months, yet 41% of CFOs report fewer than 25% of their processes are actually automated (McKinsey 2024)
- Traditional automation follows an S-curve: it excels at structured, rule-bound tasks but hits a hard ceiling at anything requiring context, inference, or ambiguity resolution
The Gap of Judgement
- The structural gap between what deterministic automation handles and what enterprise operations actually require
- Work on the far side of the gap is probabilistic, not procedural — requiring inference, cross-system reasoning, and exception handling
- LLMs are the first technology capable of operating in this inference space at enterprise scale
Three Stages of Agentic Maturity
- Chatbots/Copilots — AI suggests, humans decide; bottleneck shifts slightly but persists
- True Agents — AI executes multi-step processes autonomously, calls APIs, reads/writes to systems; begins closing the gap meaningfully
- Enterprise Maturity Path — Three operational modes: Reactive (discrete tasks, read-only), Adaptive (Bayesian confidence scoring, institutional learning), Proactive (bounded autonomy with live enterprise state representation)
The Central Problem: Control, Not Capability
- The real challenge is making LLM reasoning operate within compliance, auditability, and regulatory boundaries
- Model capability benchmarks are the wrong evaluation metric; architectural design quality is what matters
- Trust must be earned through architecture, not assumed from capability
Key Architectural Components
- Enterprise Sandbox: A controlled execution boundary — agents reason and propose inside it; outputs pass through safety/governance layers before touching production systems. Agents do not replace enterprise systems; they operate inside them (SAP, ServiceNow, Excel remain unchanged)
- World Model (Simulation-Before-Act): A live representation of enterprise state that agents simulate proposed actions against before committing. Example: a vendor payment term change triggers simulation revealing 47 open invoices, 12 pending POs, 3 blocked payments — constraint violations caught before any production system is touched
- Context Graphs: Track relationships between agent actions, predictions, and outcomes over time — enabling active learning and confidence calibration, not just after-the-fact auditability
- Multi-Layer Governance Stack: Pre-action simulation → human approval gates (with full reasoning chain visible) → append-only audit trails with field-level before/after state
Phased Deployment Protocol
| Phase | Mode | Human Role | Purpose |
|---|---|---|---|
| 1 | Shadow Mode | No action taken | Calibrate accuracy on real data |
| 2 | Assisted Mode | Review & approve all | Surface failure modes and edge cases |
| 3 | Supervised Autonomy | Handle exceptions only | Empirically validate reliability thresholds |
| 4 | Full Autonomy | Govern policy & audit | Bounded execution; justified by prior phase data |
Practical Takeaways
- Reframe the question: Stop asking ‘will AI disrupt our industry?’ Start asking ‘can we finally automate what traditional automation always failed to automate?’
- Architecture over capability: Evaluate AI deployments on governance design quality, not model benchmarks
- No rip-and-replace required: The integration philosophy layers agentic reasoning above existing infrastructure — SAP, ServiceNow, and Excel remain the systems of record
- Start shadow mode now: The phased approach transforms trust from a prerequisite into an empirically earned outcome — you do not need to decide upfront whether to trust AI with critical processes
- The fast-follower strategy is broken: Unlike ERP or cloud migrations, agentic AI builds compounding institutional memory (validated exception patterns, calibrated confidence models) that cannot be purchased — only grown through deployment time. Every month of delay is lost institutional learning that competitors are actively accumulating
- Governance imagination is the scarce resource: The organizations most likely to succeed are not the most technically sophisticated — they are the ones that treat deployment as a governance design problem