GPT-5.4 beat human performance on desktop tasks and missed a question a child would get right. Both are true. Here's…
GPT-5.4 beat human performance on desktop tasks and missed a question a child would get right. Both are true. Here’s what to do with that.
Original article: https://natesnewsletter.substack.com/p/i-tested-gpt-54-against-claude-and
Author: Nate Jones | Published: March 8, 2026
Source: Nate’s Substack
Summary
Nate Jones ran structured blind evaluations of GPT-5.4 against Claude Opus 4.6 and Gemini 3.1 across six real-world tasks — not vibes, not one-afternoon impressions, but actual scored evals with independent judging. The result is a nuanced picture that cuts through the hype in both directions.
The Core Finding: The Thinking Toggle
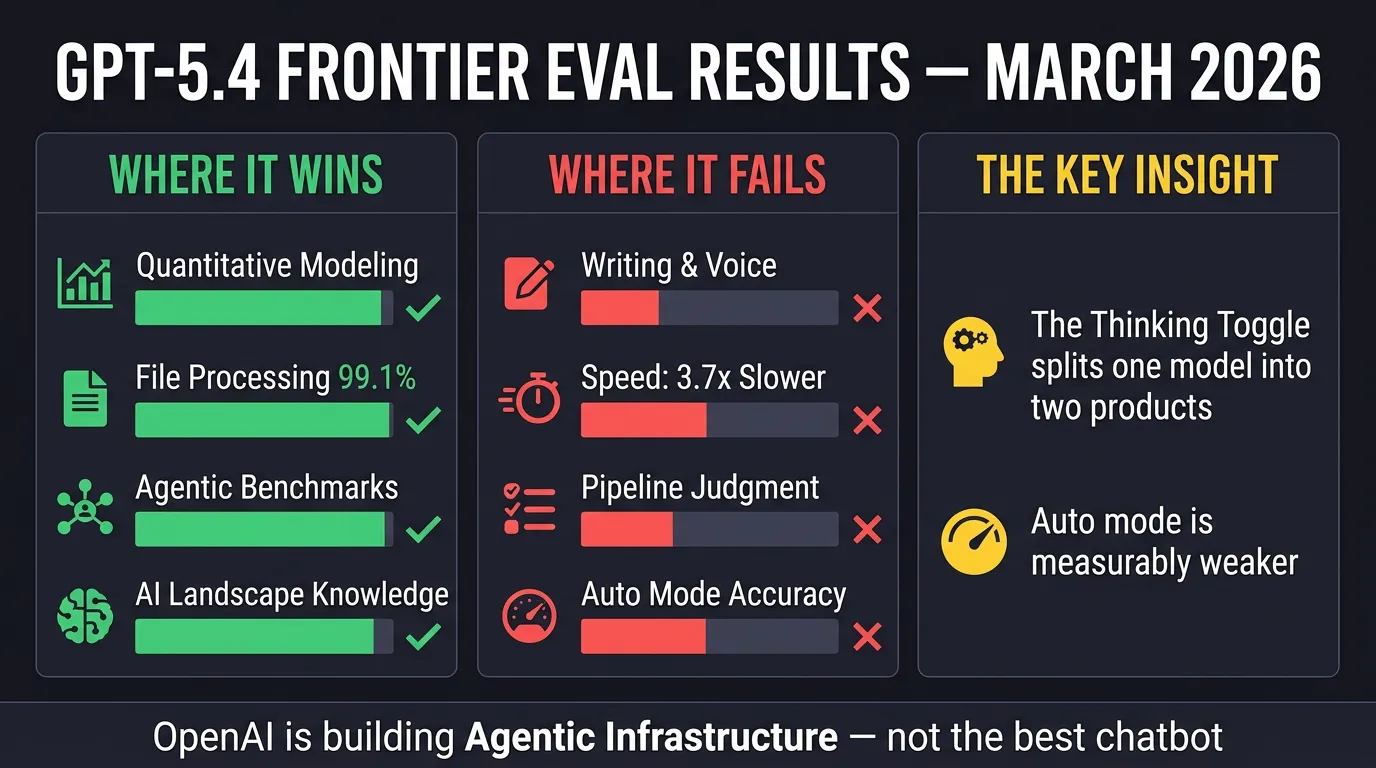
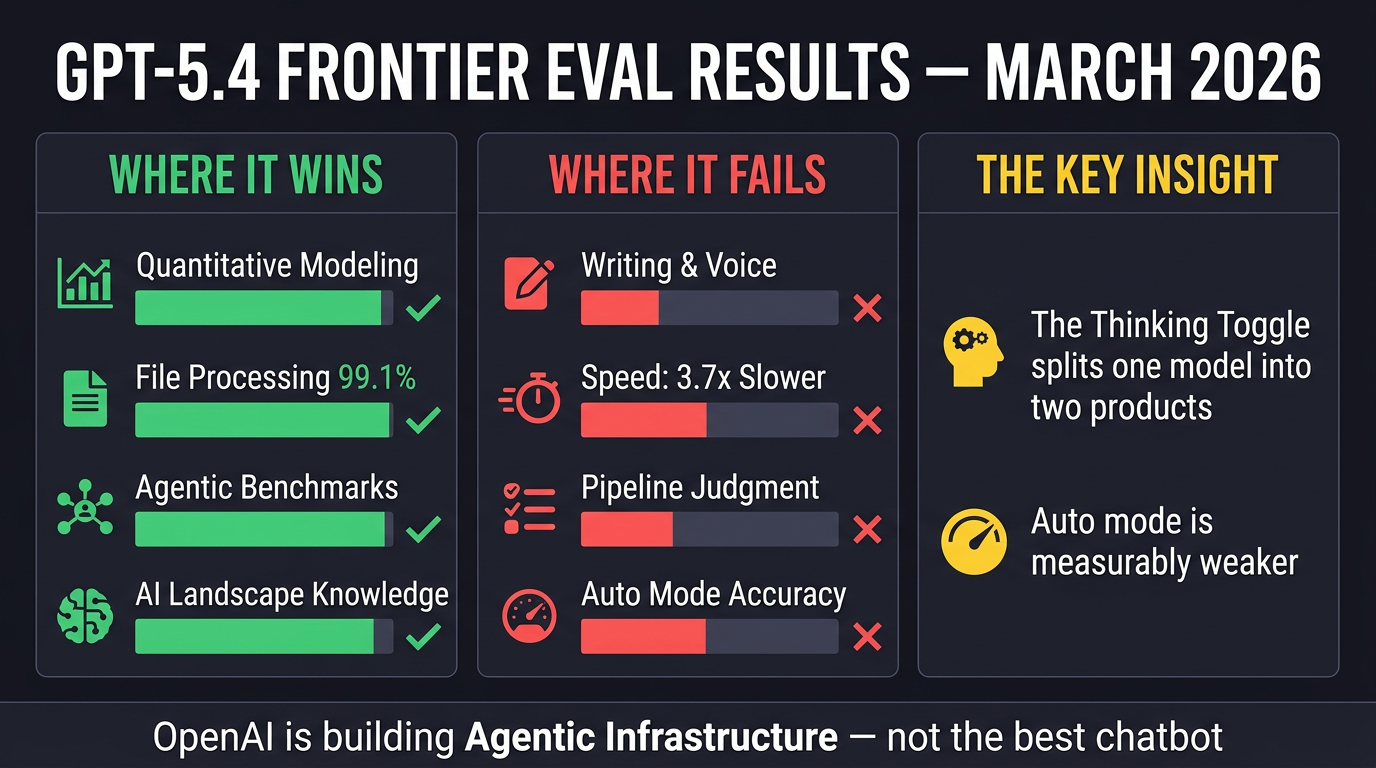
The single most important discovery is that GPT-5.4 in Thinking mode and GPT-5.4 in Auto mode are essentially two different products. In Thinking mode, it’s a genuine frontier competitor. In Auto mode (what the vast majority of ChatGPT’s billion users actually experience), it collapses — accuracy drops 2.0–2.5 points on a 5-point scale, it names wrong Nobel Prize winners, misestimates company revenue by 3x, and never flags its own low confidence even when it spots its own errors. There is no warning label. If you use GPT-5.4, the thinking toggle is the first thing you need to understand.
Where GPT-5.4 Genuinely Wins
-
Quantitative modelling: Built a superior 6-tab spreadsheet with Pythagorean win expectation, Elo-like rating system, and Poisson-binomial distribution — then wrote an unprompted, honest self-critique of its own limitations. Claude’s model was cleaner but statistically weaker.
-
File processing: Achieved 99.1% document-type coverage (461/465 files) across CSVs, Excel, JSON, PDFs, scanned receipts, corrupted JSON, and multi-tab spreadsheets. Claude came in at 75% because it skipped Excel files rather than install a three-second dependency.
-
AI self-knowledge: Most comprehensive map of the competitive model landscape across all frontier providers, with minor imprecisions but no major blind spots.
Where GPT-5.4 Falls Apart
-
Writing quality: Not close. In blind tests, Opus 4.6 produced prose that Nate’s judge called “the single finest piece of pastiche in the entire set.” GPT-5.4 is technically adequate but tonally inconsistent. For anything requiring voice — strategy memos, editorial, executive communications — Opus is still the clear choice.
-
Speed: 56 minutes vs Claude’s 15 minutes on the complex schema migration task. GPT-5.4 produced more (4,050-line script vs 1,800 lines), but Claude’s output was more immediately usable.
-
The Pipeline Problem: GPT-5.4 treats tasks as pipelines to execute, not problems to understand. On the schema migration eval, it found 278 customer records when ~176 were expected, created 13 status values where the business reality was 4–5, and allowed ghost records (“Test Customer,” “Mickey Mouse,” “Asdf Asdf”) straight into its production database. It built an impressive technical pipeline and never once asked whether the output made sense.
The Steinberger Signal
Three weeks before this release, Peter Steinberger — creator of OpenClaw, the viral AI agent with 247,000 GitHub stars that used Claude as its default model — joined OpenAI. Three weeks later, GPT-5.4 shipped with native computer use, tool search (lazy-loading tool definitions to cut token usage 47%), million-token context, and agentic benchmarks that surpass human baselines on desktop navigation (75% vs 72.4% human).
What OpenAI Is Actually Building
Every benchmark OpenAI chose to promote was an agentic benchmark. The emphasis is: sustained workflows, tool ecosystems, operating software, not single-turn intelligence. GPT-5.4 folds its coding variant into the mainline model and adds infrastructure for agents to discover tools at runtime. For organisations building on large tool ecosystems (dozens of MCP servers), this is a real architectural improvement.
Practical Takeaways
| Use Case | Recommendation |
|---|---|
| Writing, voice, strategy memos | Claude Opus 4.6 |
| Agentic systems, tool-heavy pipelines | GPT-5.4 (Thinking mode) |
| Complex quantitative modelling | GPT-5.4 (Thinking mode) |
| Exhaustive file processing | GPT-5.4 (Thinking mode) |
| Speed-sensitive iteration | Claude Opus 4.6 |
| Everything else (Auto mode ChatGPT) | Be cautious — test first |
The models are converging on capability and diverging on philosophy. Pay less attention to who won the benchmark, and more to what the benchmark was measuring.
Infographics
Portrait (9:16)

Landscape (16:9)
Processed by Angus on 2026-03-08. Part of the Nate’s Substack monitor workflow.
Infographics