Executive Briefing: 90% of companies invested in AI. The 5 operations separating the 40% who got results from everyone…
Executive Briefing: 90% of companies invested in AI. The 5 operations separating the 40% who got results from everyone else.
Original article: https://natesnewsletter.substack.com/p/executive-briefing-90-of-companies
Author: Nate Jones | Published: March 2, 2026
Source: Nate’s Substack
Summary
90% of companies report investing in AI. Fewer than 40% report meaningful bottom-line impact. The usual explanations — wrong tools, late start, no executive buy-in — miss the real pattern: organisations that did everything right by the conventional playbook and still can’t convert capability into output. They bought the seats, ran the workshops, hired the consultants. Their people are still doing most of the work manually.
The problem isn’t adoption. It’s that the skill the economy actually needs doesn’t have a name, doesn’t have a curriculum, and doesn’t work like any workforce skill that’s come before it. That skill is Frontier Operations.
The Bubble Mental Model
Picture a bubble. The air inside is everything AI agents can do reliably today. The air outside is everything that still requires a human. The surface — that thin membrane between the two — is where the interesting work happens: deciding what to delegate, how to verify, where to intervene, when to trust.
What most people miss: when the bubble inflates, the surface area increases. Every capability jump creates more boundary to operate at, not less. And every prior workforce skill — literacy, numeracy, coding — was a destination you could reach. Frontier operations has no fixed destination, because the surface keeps expanding outward. You can’t learn it once. You can only learn to stay on it as it moves.
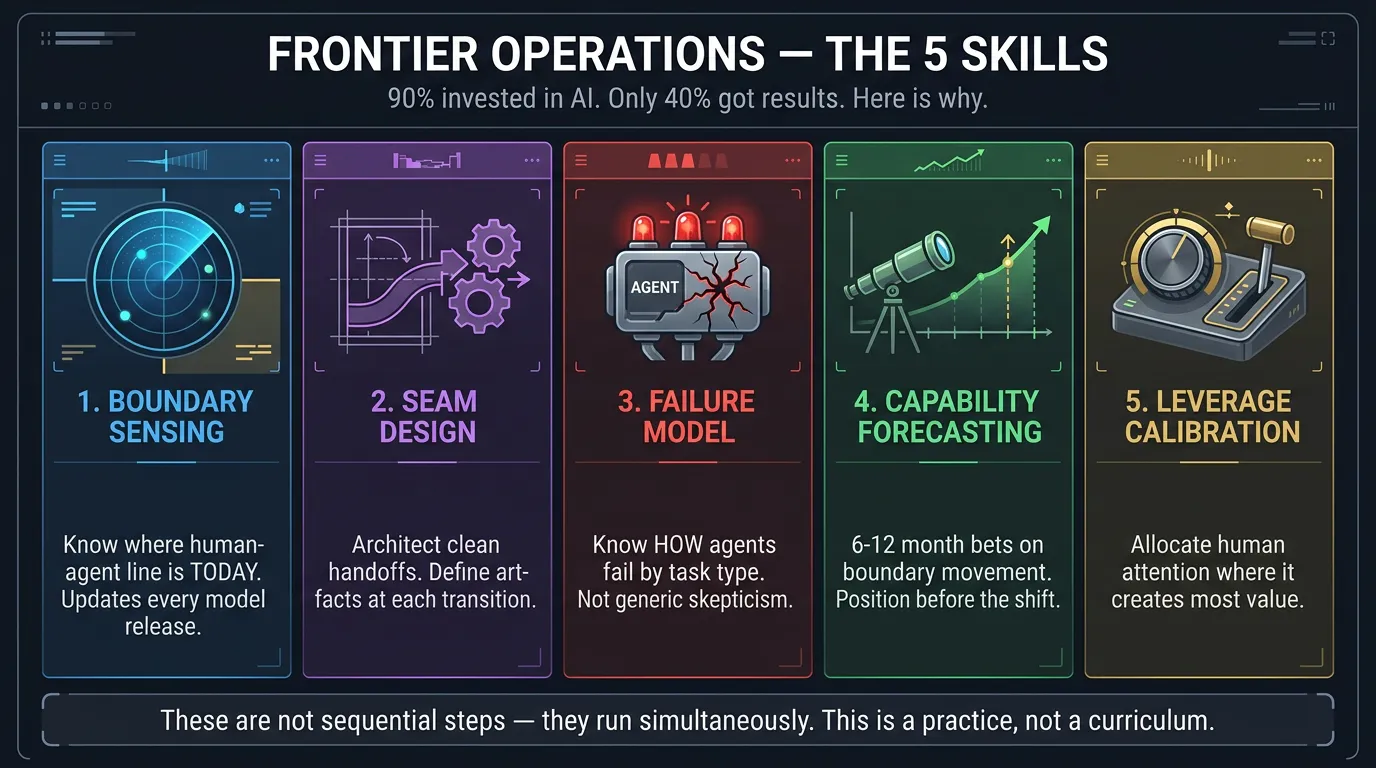
The 5 Operations of Frontier Operations
These are not sequential steps. They run simultaneously — the way driving integrates steering, speed, route awareness, and hazard perception all at once.
1. Boundary Sensing
The ability to maintain accurate, up-to-date operational intuition about where the human-agent boundary sits for a given domain.
This is not static. Sonnet 4.5 scored below 20% on long-context retrieval. Opus 4.6 scores 76% on the same benchmark at one million tokens. A person who calibrated their boundary sense against last quarter’s model and hasn’t updated is now either over-trusting or under-using.
What good looks like: A product manager who lets the agent handle market sizing and feature comparison (now safely inside the bubble), but reserves stakeholder-dynamics analysis for herself — and updated that boundary from the quarter before when she was doing feature comparison manually too.
2. Seam Design
The ability to structure work so that transitions between human and agent phases are clean, verifiable, and recoverable.
This is an architectural skill. The right question: if I break this project into seven phases, which three are fully agent-executable, which two need human-in-the-loop, and which two are irreducibly human? What artifacts pass between each phase? What do I need to see at each transition?
The reason this is a distinct skill: the seam that was in the right place last quarter is in the wrong place this quarter. The skill isn’t the design — it’s the redesign.
What good looks like: A consulting engagement manager whose research→synthesis seam used to require manual fact verification on every data point. The agent’s citation accuracy improved. She moved the seam.
3. Failure Model Maintenance
The ability to maintain an accurate, current mental model of how agents fail — not that they fail, but the specific texture and shape of failure at the current capability level.
Early LLMs failed obviously. Current frontier models fail subtly: correct-sounding analysis on a misunderstood premise. Plausible code that breaks on edge cases. Research summaries 95% accurate with the remaining 5% confidently fabricated in a way indistinguishable from the accurate parts.
The skill is differentiated failure knowledge: for Task Type A, the failure mode is X — here’s how to check efficiently. For Task Type B, the failure mode is Y — here’s a different check.
What good looks like: A corporate counsel who trusts the boilerplate contract scan but manually reviews cross-references between liability provisions and exhibits — because that’s where agents specifically fail.
4. Capability Forecasting
The ability to make reasonable short-term predictions about where the boundary will move next, and to invest accordingly.
This is not about predicting AI’s future. It’s about reading trajectory well enough to make sensible 6–12 month bets. Think of it as reading swells — a surfer doesn’t predict exactly what the next wave looks like, but positions herself where the next rideable wave is most likely to form.
What good looks like: In early 2025, a person watching coding agents progress (30 mins of autonomy → 7 hours at Rakuten → 2 weeks for a C compiler) starts investing in code review and specification skills rather than raw coding. The capability layer commoditises. The operational skill layer compounds.
What bad looks like: Investing heavily in learning one specific platform — then that platform’s advantage evaporates when the next model ships.
5. Leverage Calibration
The ability to make high-quality decisions about where to spend human attention — the scarcest resource in an agent-rich environment.
As agent capabilities increase, the bottleneck shifts from “getting things done” to “knowing which things are worth a human’s attention.” McKinsey’s framework: 2–5 humans supervising 50–100 specialised agents running an end-to-end process. With 100 streams of agent output and 8 hours per day, you cannot review everything at the same depth.
What good looks like: An engineering manager whose code review thresholds are calibrated to risk — most code flows through automated tests; anything touching authentication, billing, or data pipelines gets flagged for human review; only architectural decisions get deep engagement. She recalibrates monthly.
The Compounding Gap
A person who develops frontier operations skill six months earlier than a peer doesn’t just have a six-month head start. She has six months of updated calibration. Because capabilities are accelerating, the distance between “calibrated” and “uncalibrated” grows wider with every model release.
The person whose boundary sense was current in February and the person whose was last updated in August aren’t six months apart. They’re operating in different technological eras.
Geopolitical Snapshot
-
Japan, South Korea, Germany: Need this capacity most, least equipped to build it. Aging workforces + education systems built for fixed-target skills = structural mismatch.
-
US: Top 5% of workforce is arguably the most frontier-capable on earth. The other 95% are getting “AI literacy” training — approximately as useful as teaching someone to use a typewriter in 1995.
-
Singapore: The outlier. Budget 2026 treats workforce development as national security — 400% tax deductions on AI spending, six months of free premium AI tools for anyone completing training. They’re funding practice cycles, not classroom hours.
Organisational Models: Teams of One vs Teams of Five
Team of One: Single person with strong frontier ops skill running multiple agent workflows. Output looks like what a 5–10-person team produced 2 years ago. Cheap, fast, fragile. Works when domain is well-understood and feedback loops are tight.
Team of Five: One frontier operator (sets seams, maintains failure models, calibrates attention allocation) + 2–3 developing operators + 1–2 domain specialists. More expensive, slower, but resilient. Distributes the frontier skill.
The right structure: A lattice — Teams of One for well-understood lower-risk domains where speed matters; Teams of Five for complex, high-stakes, cross-functional domains where resilience matters. A frontier operations lead sits above, maintaining macro-level boundary sense.
The 10-Question Audit
If you answer “no” to more than 3, you have a frontier operations gap costing you real output:
-
Can you name 3 tasks delegated to agents last quarter that weren’t delegated the quarter before?
-
When the last major model update shipped, did anyone formally reassess which workflows to change?
-
Do you have someone whose explicit responsibility includes knowing where agents fail in your domain — by task type?
-
Can your team articulate which tasks they trust without review vs. always verify — and why?
-
Has anyone redesigned a human-agent workflow handoff in the last 90 days?
-
When an agent surprises (better or worse than expected), does your team capture that signal?
-
Is review depth differentiated by risk, or does everyone check everything the same way?
-
Can anyone make a credible 6-month forecast about which current tasks will migrate to agents?
-
Do you have explicit frontier operations roles, or do you expect it to emerge from day jobs?
-
If your strongest frontier operator left tomorrow, could the rest of the team maintain output?
What to Do Monday
-
Individual contributors: Track where your boundary sense is wrong. Every time an agent surprises you — better or worse than expected — log it. That’s your most valuable professional asset.
-
Managers: Look at how your team allocates attention. Are they reviewing everything at the same depth? That’s a bottleneck. Are they reviewing nothing? That’s negligence. The right answer is differentiated.
-
Executives: Do you have people whose job it is to know where the boundary is and redesign workflows when it moves? If not, you’re leaving the most consequential organisational capability of the decade to chance.
-
Policymakers: Stop building curricula. Start building flight simulators. Practice environments > classroom hours.
Infographics
Portrait (9:16)

Landscape (16:9)
Processed by Angus on 2026-03-08. Part of the Nate’s Substack monitor workflow.
Prompt Kit
Source: https://promptkit.natebjones.com/20260225_xhb_promptkit_1
Prompt Kit: Frontier Operations
Five prompts for executives who need to move past “are we using AI?” and start building the organisational capability that actually converts agent leverage into output: sensing the human-agent boundary, designing seams across it, and structuring teams to operate at it continuously.
How to use this kit: Each prompt is independent — use whichever matches your immediate need. Start with Prompt 1 (Audit) if you’re unsure where you stand. Prompt 2 (Seam Redesign) is the most immediately tactical — bring a specific workflow.
Prompt 1: Frontier Operations Maturity Audit
Job: Diagnose your organisation’s current capability across all five frontier operations — boundary sensing, seam design, failure model maintenance, capability forecasting, and leverage calibration.
When to use: When you suspect your org is under-leveraging AI or over-trusting it, and need a structured assessment to find the gaps.
What you’ll get: A maturity rating for each operation, specific evidence of where calibration has drifted, and a prioritised action plan.
Prompt 2: Workflow Seam Redesign
Job: Take a specific workflow and redesign where the human-agent seams sit — what the agent owns, what the human owns, what artifacts pass between them, and what verification checks go at each transition.
When to use: When a workflow feels wrong — humans doing too much, agents doing too much unsupervised, or handoffs keep breaking.
What you’ll get: Current-state seam map, redesigned workflow with explicit seam placement, artifact definitions, verification protocols, and triggers for when to move the seams again.
Prompt 3: Teams of One / Teams of Five Org Structure Planner
Job: Design team composition for a function using the Teams of One and Teams of Five model — determining which domains get solo operators, which get pods, and how they connect.
When to use: When restructuring a function around agent leverage and deciding headcount, composition, and lattice structure.
Prompt 4: Frontier Operator Hiring Protocol
Job: Build an interview and assessment protocol for identifying people with genuine frontier operations skill — not tool proficiency, but the integrated ability to sense boundaries, design seams, maintain failure models, forecast capability shifts, and calibrate attention.
What you’ll get: Interview questions mapped to each of the five operations, scoring rubric, red-flag indicators, and a practical assessment exercise.
Prompt 5: Attention Allocation Audit
Job: Assess how a team distributes human review attention across agent-assisted work, identify where attention is misallocated, and build a risk-calibrated triage protocol.
When to use: When your team reviews everything at the same depth (bottleneck masquerading as diligence) or reviews nothing (negligence masquerading as trust).
What you’ll get: Current-state attention map, redesigned triage protocol with deep/light/automated tiers, recalibration triggers, and attention recovered estimate.
Infographics