Every workaround you built for the last model is now breaking the next one. The 4-question audit + prompts to fix it.
Summary: Every workaround you built for the last model is now breaking the next one
Main Thesis
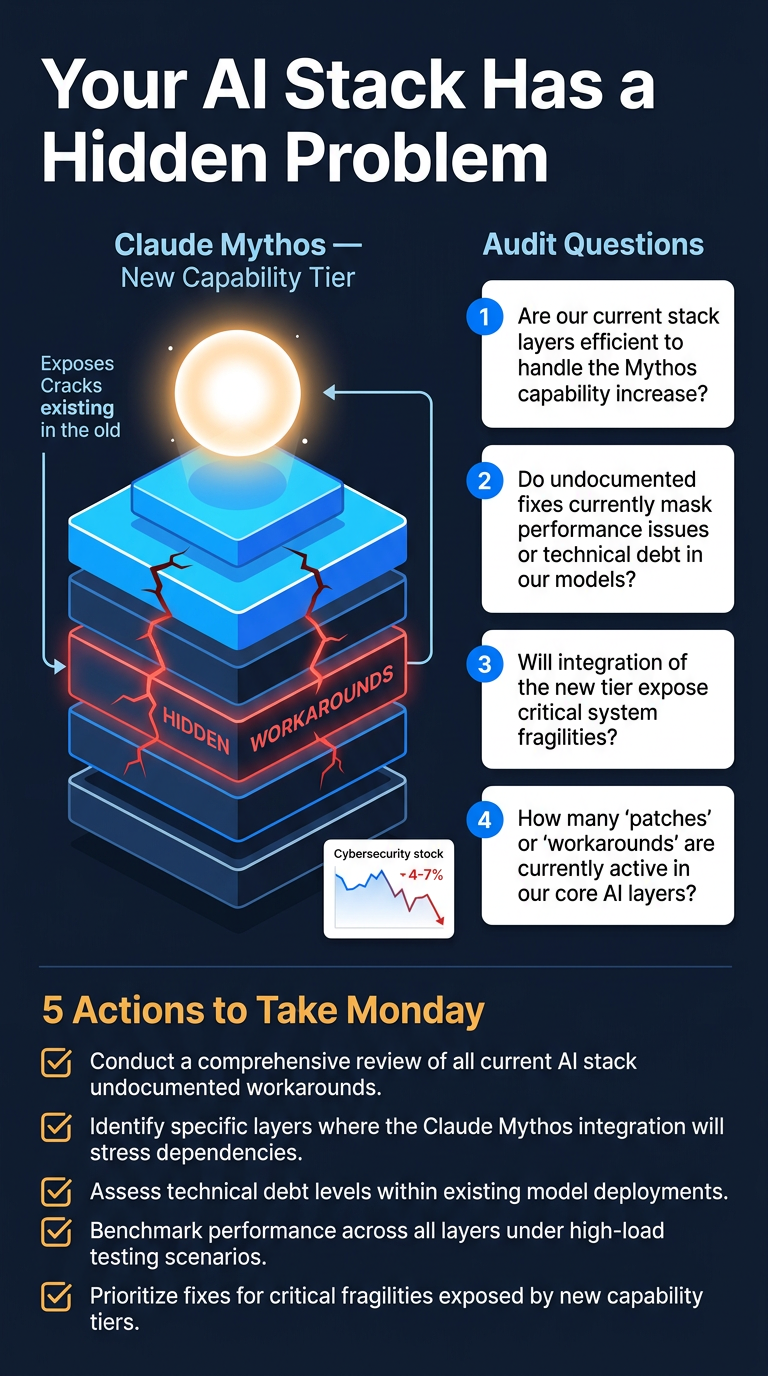
When AI models make a significant capability leap — as Anthropic’s new Claude Mythos reportedly does — the hidden layer of workarounds and compensations that teams built for previous models’ weaknesses can actively break or degrade the new system. Most teams don’t even recognise these workarounds as workarounds anymore.
Key Context: What is Claude Mythos?
- Anthropic’s most powerful model to date — not an incremental update, but a new capability tier above Opus
- Described in Anthropic’s own draft language as “currently far ahead of any other AI model in cyber capabilities”
- Cybersecurity stocks dropped 4.5–7% when this language leaked
- Mythos is being released to cyber-defense organisations first, before general release — a deliberate slow-roll that signals Anthropic takes its own warnings seriously
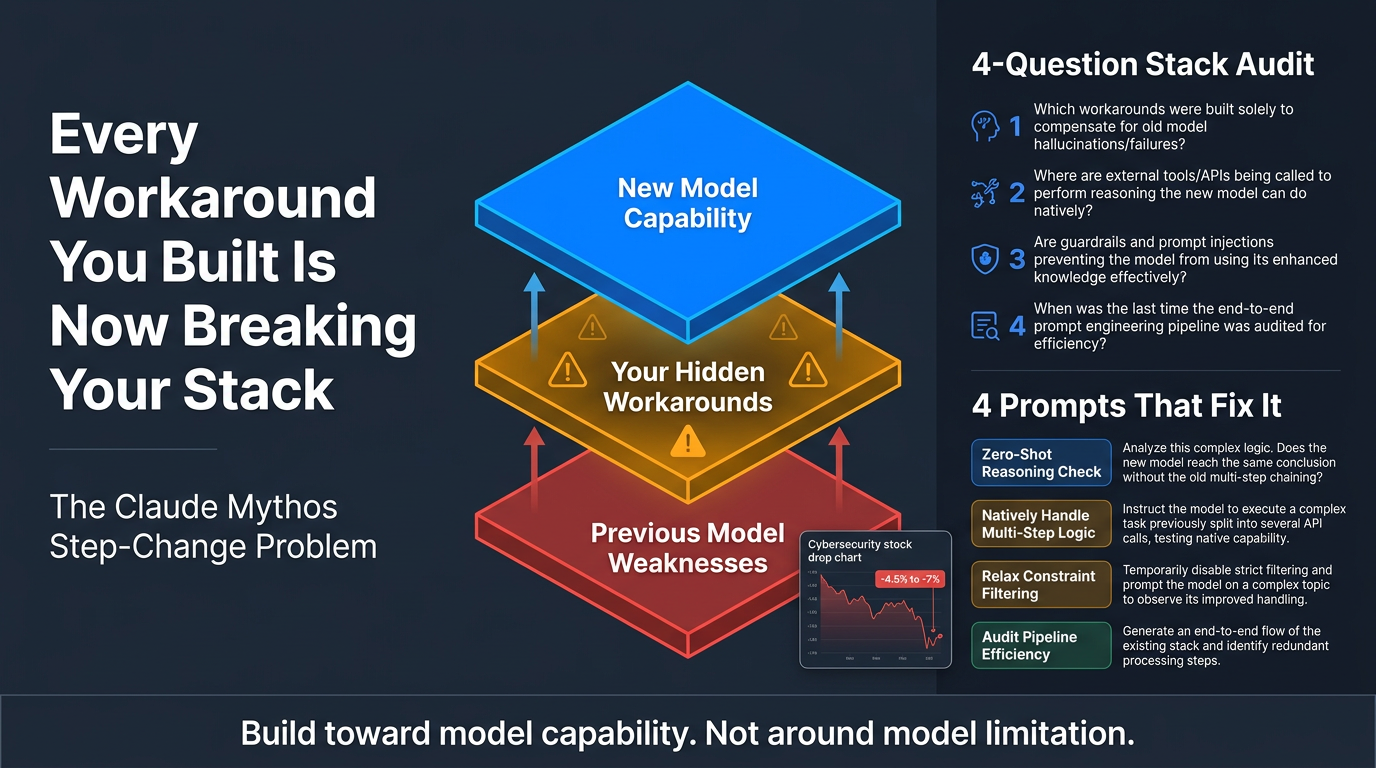
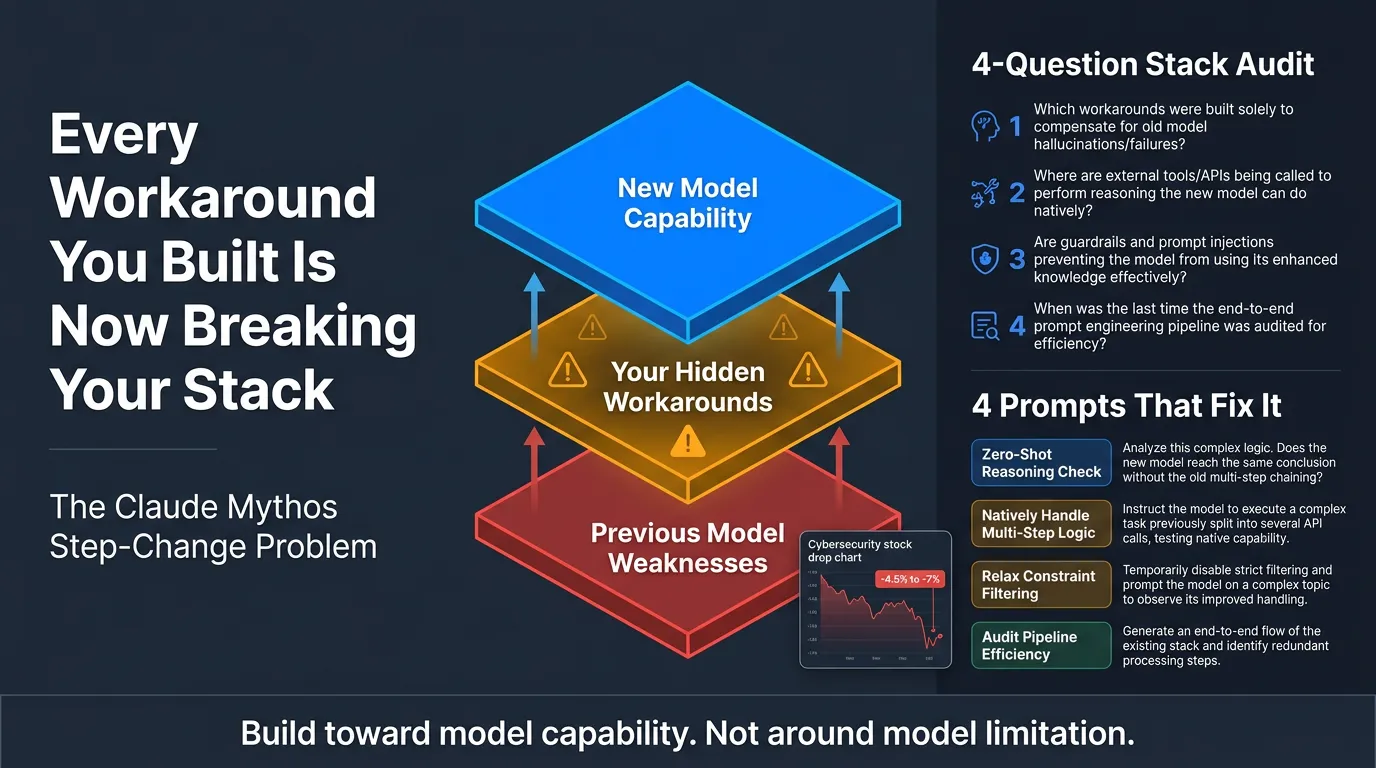
The Core Problem
- Every production AI system contains an invisible layer of compensations for the previous model’s weaknesses
- Teams stop seeing these as workarounds over time — they become the architecture
- A step-change model doesn’t automatically make your system better; it can make it work worse by invalidating those hidden assumptions
- The media focuses on what the new model can do; Nate focuses on what it exposes in your existing stack
Key Frameworks & Findings
1. The Simplification Pattern
- Teams building production agents are converging on the same counter-intuitive finding: simpler is more durable
- Engineering instincts push toward complexity; model step-changes punish it
2. The Bitter Lesson for Builders
- References a 70-year pattern in AI research: methods that lean on the model’s raw capability consistently outperform those that hardcode human knowledge/workarounds
- Builder communities are largely ignoring this lesson
- Klarna case study is cited as an example of what ignoring it costs
3. The Four-Question Audit
One diagnostic question per layer of your AI stack to run the day a new model drops:
- Designed to surface which parts of your system rely on compensating for model weaknesses rather than leveraging model strengths
- Produces concrete before-and-after examples
4. Four Prompts That Do the Work
- Line-by-line system prompt audit — finds compensations baked into prompts
- Outcome-based rewriter — rewrites prompts around results, not model quirks
- Org-level dependency map — surfaces team-wide reliance on workarounds
- Step-change readiness plan — prepares your stack before a new model ships
Practical Takeaways (Five Things to Do Monday)
- Act before Mythos ships, not after
- Audit your system prompts for language that exists to manage model weaknesses
- Map dependencies across your org that assume current model behaviour
- Adopt a design principle: build toward model capability, not around model limitation
- Treat every major model release as an architectural audit trigger, not just a version bump
Bottom Line
The article argues that the real risk of a model step-change is not external — it’s internal. The systems you’ve already shipped are the vulnerability. Teams that audit and simplify now will compound the gains from Mythos; teams that don’t will find their carefully engineered workarounds actively fighting the new model’s strengths.