AI Agents of the Week: Papers You Should Know About (Feb 22, 2026)
Original newsletter: LLM Watch — AI Agents of the Week (Feb 22, 2026)
Overview
This week’s LLM Watch roundup covers six research papers that collectively advance the state of AI agents across four key dimensions: memory and skill reuse, multi-agent planning, trust and safety, and scientific computing. The throughline is clear: the architecture of agent collaboration matters as much as individual model capability.
Key Papers
1. IntentCUA — Intent-Level Skill Abstraction for Computer-Use Agents
IntentCUA introduces intent-level representations that abstract raw interaction traces into reusable skills, allowing a computer-use agent to stop re-solving the same subproblems from scratch. A Planner, Plan-Optimizer, and Critic coordinate over shared memory to stabilize long-horizon execution. Results: 74.83% task success rate on desktop automation benchmarks, with a Step Efficiency Ratio of 0.91 — meaning it wastes almost no steps.
Why it matters: Long-horizon desktop automation is notoriously brittle. Skill abstraction is the right abstraction layer — it’s how humans work too.
2. Wink — Recovering from Misbehaviors in Coding Agents
A production-deployed system (at a real software company) for detecting and recovering from coding agent failures. The paper taxonomizes three major failure modes: Specification Drift, Reasoning Problems, and Tool Call Failures — found in approximately 30% of all agent trajectories. Wink’s lightweight self-intervention resolves 90% of single-intervention misbehaviors and achieved statistically significant reductions in engineer interventions during live A/B testing.
Why it matters: This is a rare paper with real production data. 30% failure rate on trajectories is sobering — and Wink’s 90% resolution rate without human intervention is impressive.
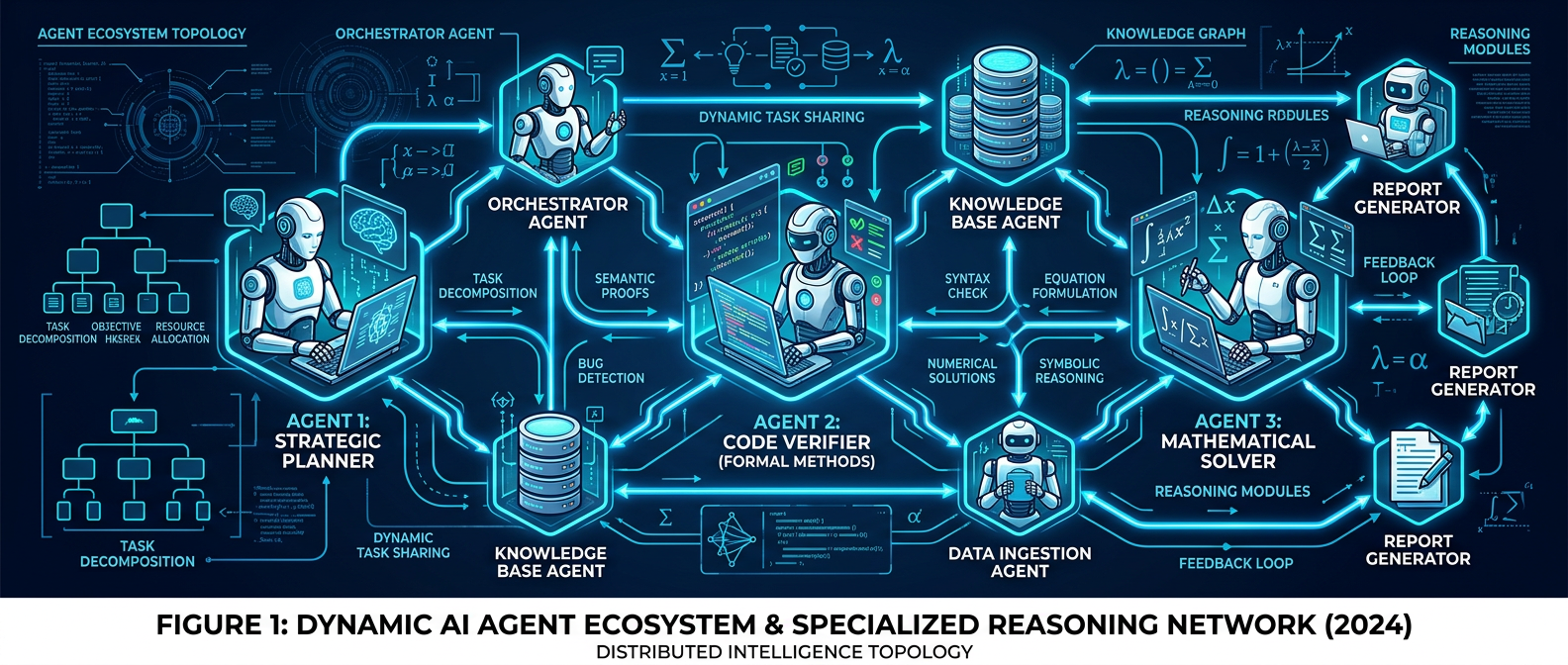
3. AgentConductor — Topology Evolution for Multi-Agent Code Generation
Instead of fixed communication graphs, AgentConductor uses reinforcement learning to evolve the interaction topology of a multi-agent system based on task difficulty. Its density-aware layered DAG construction reduces token costs by 68% while improving pass@1 accuracy by up to 14.6% over baselines. Dynamic topology wins over static wiring.
Why it matters: Token efficiency + accuracy improvement simultaneously is unusual. The RL-topology approach is elegant — match the coordination overhead to the actual task complexity.
4. How AI Coding Agents Communicate — Pull Request Analysis
An empirical study of pull requests created by five AI coding agents on GitHub, analyzing how description characteristics correlate with reviewer engagement and merge outcomes. Spoiler: presentation style matters. Agents that write clearer, better-structured PRs get better review responses and higher merge rates.
Why it matters: Practical and immediately actionable. If you’re deploying coding agents, their communication style is a first-class concern.
5. CowCorpus — Modeling Human Intervention in Web Agents
Introduces a taxonomy of human intervention patterns in web agents and trains models to predict when a user is likely to intervene. Achieves 61.4–63.4% improvement over baselines in intervention prediction. This is the groundwork for agents that proactively request guidance at the right moments rather than barreling through or pestering unnecessarily.
Why it matters: The “when to ask for help” problem is underappreciated. Agents that interrupt too much are annoying; agents that never ask get stuck or go off the rails.
6. AutoNumerics — Autonomous Multi-Agent PDE Solver
Applies multi-agent orchestration to scientific computing: AutoNumerics autonomously designs and verifies numerical solvers for partial differential equations (PDEs) across 24 canonical problems — without domain-specific tuning. Bridges the gap between LLM reasoning and formal numerical methods.
Why it matters: Scientific computing is one of the last bastions of “you need deep human expertise.” AutoNumerics is a serious step toward agentic science.
Practical Takeaways
- Skill reuse > re-solving: IntentCUA proves that abstracting intent from raw trajectories pays off in both efficiency and accuracy
- Failure is common: ~30% trajectory failure in production coding agents (Wink) — monitoring and recovery aren’t optional
- Topology matters: Fixed multi-agent graphs are leaving performance on the table; adaptive topology (AgentConductor) cuts costs and improves results simultaneously
- Communication style counts: Your AI coding agent’s PR writing quality affects human review outcomes
- Intervention prediction: Teaching agents when to pause and ask is a genuine research frontier
- Science is next: Multi-agent systems are approaching autonomous scientific problem-solving
⚠️ Note: The original LLM Watch article may be paywalled. The arxiv links above are freely accessible.
Infographics