AI Agents of the Week: Papers You...

AI Agents of the Week – LLM Watch (March 8, 2026)
Main Thesis
This week’s research roundup highlights meaningful progress across five core challenge areas for autonomous AI agents: memory management, long-horizon planning, multi-agent collaboration, safety/evaluation, and practical tooling.
Key Findings
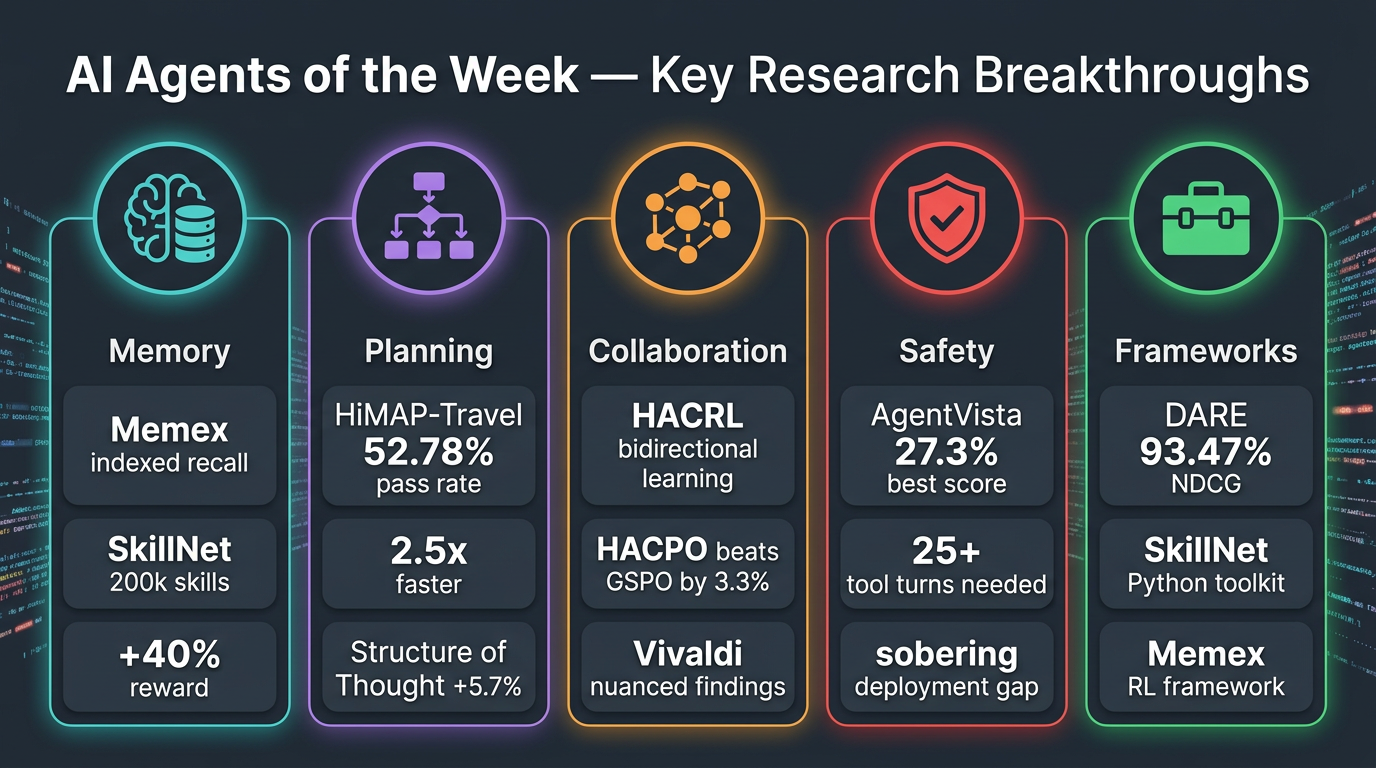
🧠 Memory & Continual Learning
- Memex(RL): Solves the context window bottleneck by indexing past interactions externally, allowing agents to retrieve full-fidelity memories on demand — avoiding lossy summarization.
- SkillNet: Builds a library of 200,000+ reusable skills, improving average rewards by 40% and cutting execution steps by 30% across benchmarks. Agents stop “reinventing the wheel.”
🗺️ Planning & Environment Interaction
- HiMAP-Travel: Hierarchical multi-agent framework splits travel planning into strategic + parallel day-level execution. Achieves 52.78% validation pass rate on TravelPlanner (+8.67pp over baselines) with 2.5x lower latency.
- T2S-Bench: “Structure of Thought” prompting yields +5.7% improvement across 8 text tasks; fine-tuning pushes this to +8.6%. How agents organize information matters as much as what they know.
🤝 Multi-Agent Collaboration
- HACRL: Enables heterogeneous agents to learn from each other via verified rollout sharing. Their HACPO algorithm beats GSPO by 3.3% using only half the rollout cost.
- Vivaldi: Role-structured multi-agent system for physiological time series. Key nuance: agentic pipelines help non-thinking models (+6.9 to +9.7 points) but can hurt thinking models (−14 points in relevance). Agentic reasoning is not universally beneficial.
🔒 Trust, Verification & Safety
- AgentVista: A rigorous benchmark across 25 sub-domains. Even the best model (Gemini-3-Pro with tools) achieves only 27.3% overall accuracy. Hard tasks require 25+ tool-calling turns, exposing how far agents are from reliable real-world use.
- Vivaldi reinforces that explicit tool-based computation wins for codifiable metrics; subjective targets show limited gains — value lies in selective externalization of computation.
🛠️ Tools & Frameworks
- DARE: Distribution-aware retrieval for R’s statistical ecosystem, achieving 93.47% NDCG@10 — outperforming state-of-the-art embedding models by up to 17% with fewer parameters. RCodingAgent shows strong downstream gains.
- SkillNet releases an interactive platform and Python toolkit alongside its skill repository for immediate developer use.
- Memex(RL) provides an RL framework specifically for optimizing memory retrieval operations.
Practical Takeaways
- Don’t rely on context windows alone — external indexed memory (Memex(RL)) is a superior architecture for long-running agents.
- Reusable skill libraries dramatically cut redundant computation; SkillNet’s open toolkit is worth exploring now.
- Parallelized hierarchical planning (HiMAP-Travel) is a viable pattern for complex constrained tasks.
- Test before assuming agentic = better — Vivaldi’s results show thinking models can be degraded by agentic pipelines.
- Current agent benchmarks are brutally hard — AgentVista’s 27.3% ceiling should calibrate expectations for production deployment.
- Structured prompting (Structure of Thought) is a low-cost, high-value technique worth applying immediately.