AI Agents of the Week: Papers You...
AI Agents of the Week — LLM Watch (Feb 15, 2026)
Main Thesis
This week’s AI agent research challenges several prevailing assumptions about how to build, guide, and scale autonomous agents — from documentation practices to multi-agent coordination and compute allocation.
Key Findings
🧠 Memory & Context
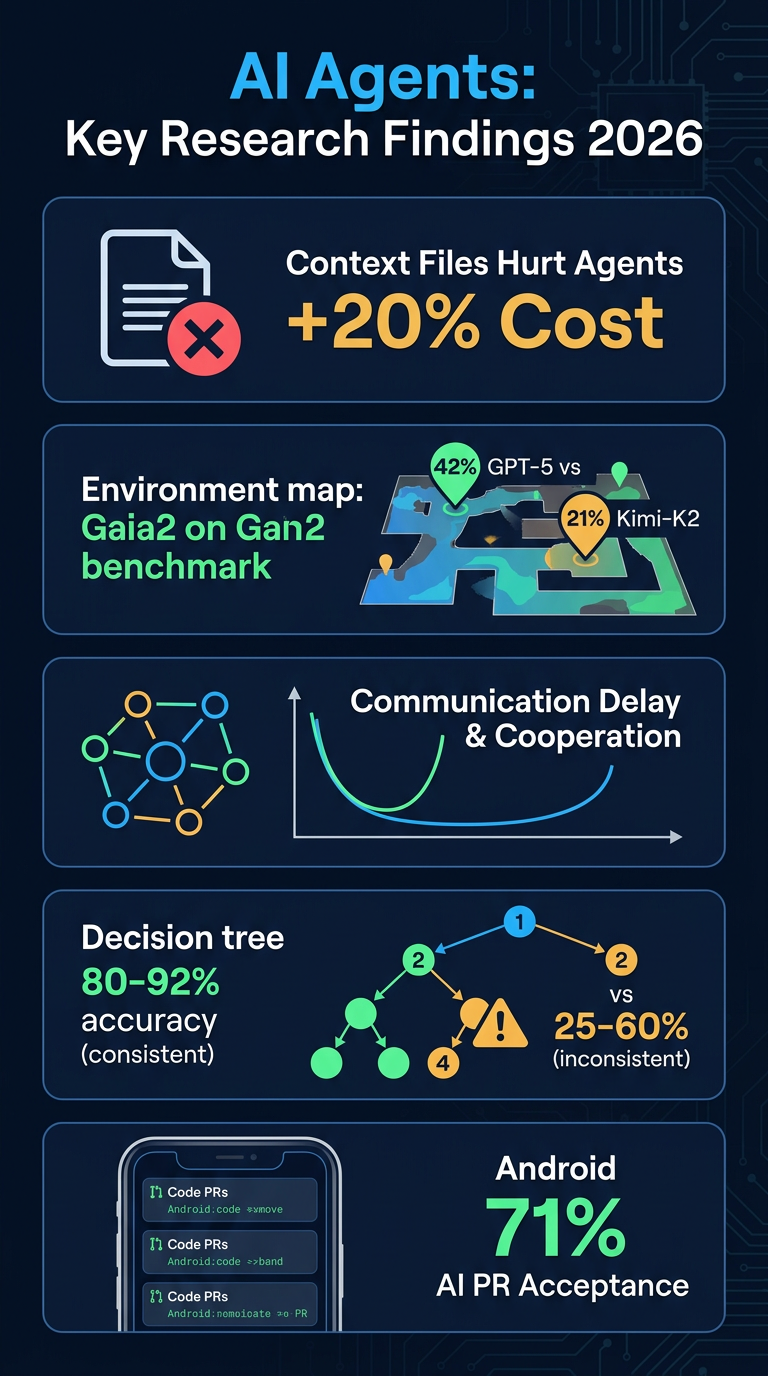
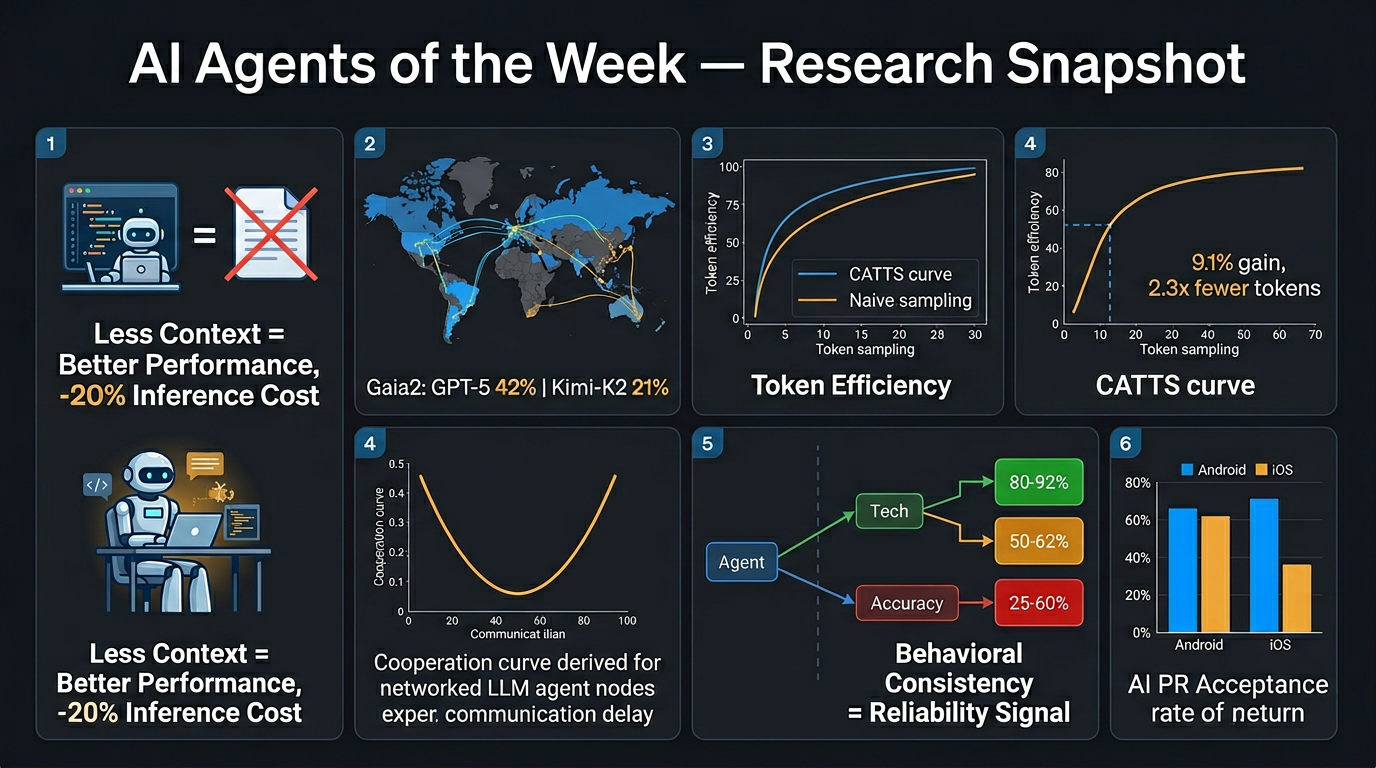
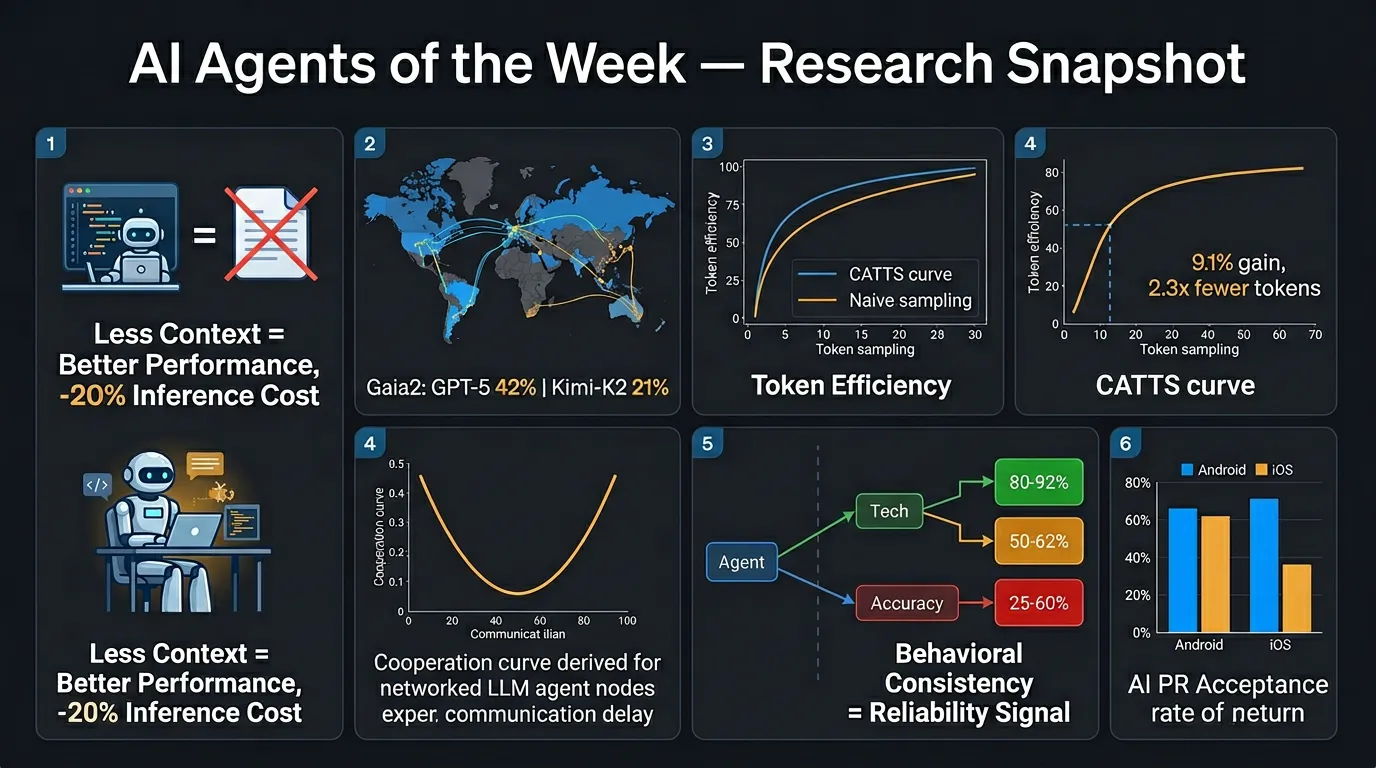
- AGENTS.md files hurt performance: Contrary to popular practice, repository-level context files reduce task success rates for coding agents while increasing inference costs by >20%.
- Less is more: Minimal or no instructions outperform comprehensive documentation, suggesting unnecessary constraints impede agents rather than help them.
🗺️ Planning & Environment
- Gaia2 benchmark: Introduces dynamic, evolving environments independent of agent actions. Best results: GPT-5 (high) at 42% pass@1 but struggles with time-sensitive tasks; Kimi-K2 (open-source) at 21% pass@1.
- CATTS (Confidence-Aware Test-Time Scaling): Outperforms naive uniform compute sampling by up to 9.1% on WebArena-Lite while using 2.3x fewer tokens — smart allocation beats brute-force compute.
🤝 Multi-Agent Collaboration
- Communication delays create U-shaped cooperation: Moderate delays cause LLM agents to exploit slower peers; excessive delay paradoxically reduces exploitation cycles.
- FLCOA framework: Five-layer model showing that low-level factors like communication resources fundamentally shape multi-agent cooperation — largely overlooked in current system design.
- LAVES: Hierarchical multi-agent system for educational video generation achieves >1 million videos/day throughput with a 95% cost reduction vs. industry standards.
🔒 Trust & Safety
- Behavioral inconsistency predicts failure: ReAct agents produce 2.0–4.2 distinct action sequences per 10 identical runs. Tasks with consistent paths achieve 80–92% accuracy; highly inconsistent tasks drop to 25–60%.
- 69% of divergence occurs at step 2, meaning early decisions cascade into downstream failures — making early-step monitoring a practical intervention point.
🛠️ Tools & Benchmarks
- Mobile dev AI agents: Study of 2,901 AI-authored PRs across 193 Android/iOS repos. Android sees 2x more AI PRs with higher acceptance (71% vs. 63% iOS). Routine tasks succeed most; structural refactors lag.
- AmbiBench: First benchmark using an instruction clarity taxonomy, shifting evaluation toward bidirectional intent alignment — addressing the reality that users often fail to articulate precise directives upfront.
Practical Takeaways
- Strip down AGENTS.md files — comprehensive instructions may be actively harming your coding agents.
- Monitor behavioral consistency as a real-time reliability signal; early divergence is a strong failure predictor.
- Use confidence-aware compute allocation rather than scaling uniformly for better efficiency and performance.
- Design multi-agent systems with communication latency in mind — it shapes cooperation in non-obvious ways.
- Evaluate agents on ambiguous instructions, not just clean ones — AmbiBench highlights a critical gap in current benchmarking.