AI Agents of the Week: Papers You...
AI Agents of the Week – LLM Watch (Feb 8, 2026)
Main Thesis
The frontier of AI agent research is rapidly maturing across five dimensions: architecture design, multi-agent collaboration, planning under uncertainty, safety, and evaluation. Agents are evolving from simple chatbots into modular, self-improving systems capable of handling complex, long-horizon tasks — but new challenges around reliability, safety, and interpretability are emerging in parallel.
Key Findings
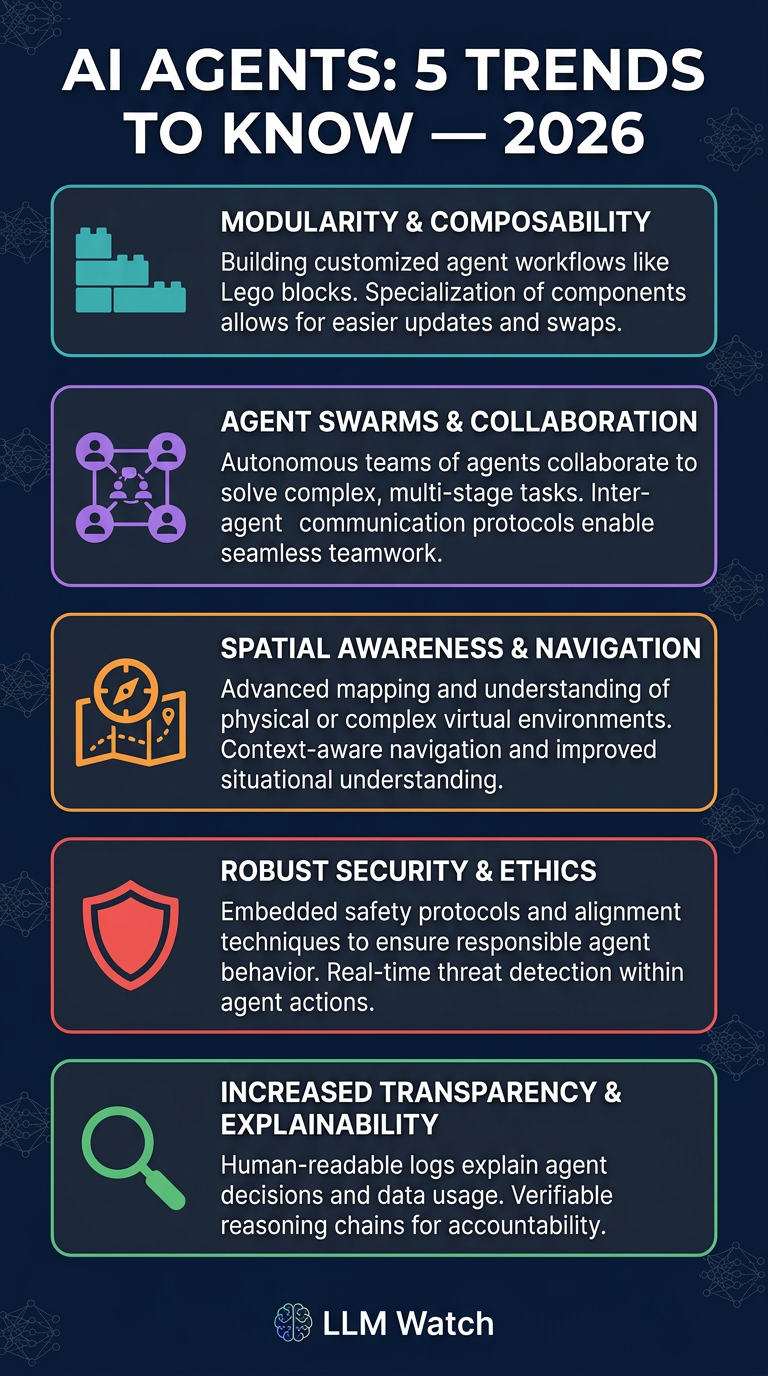
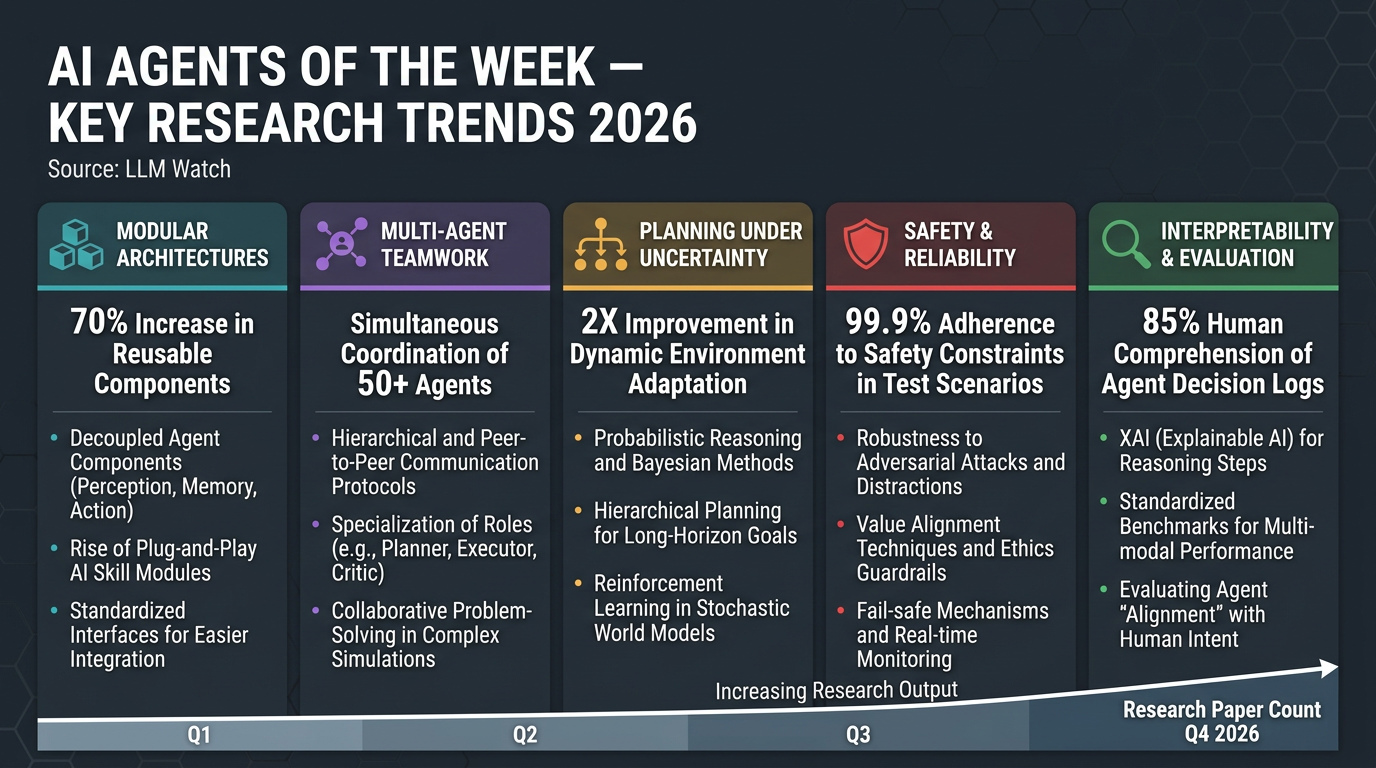
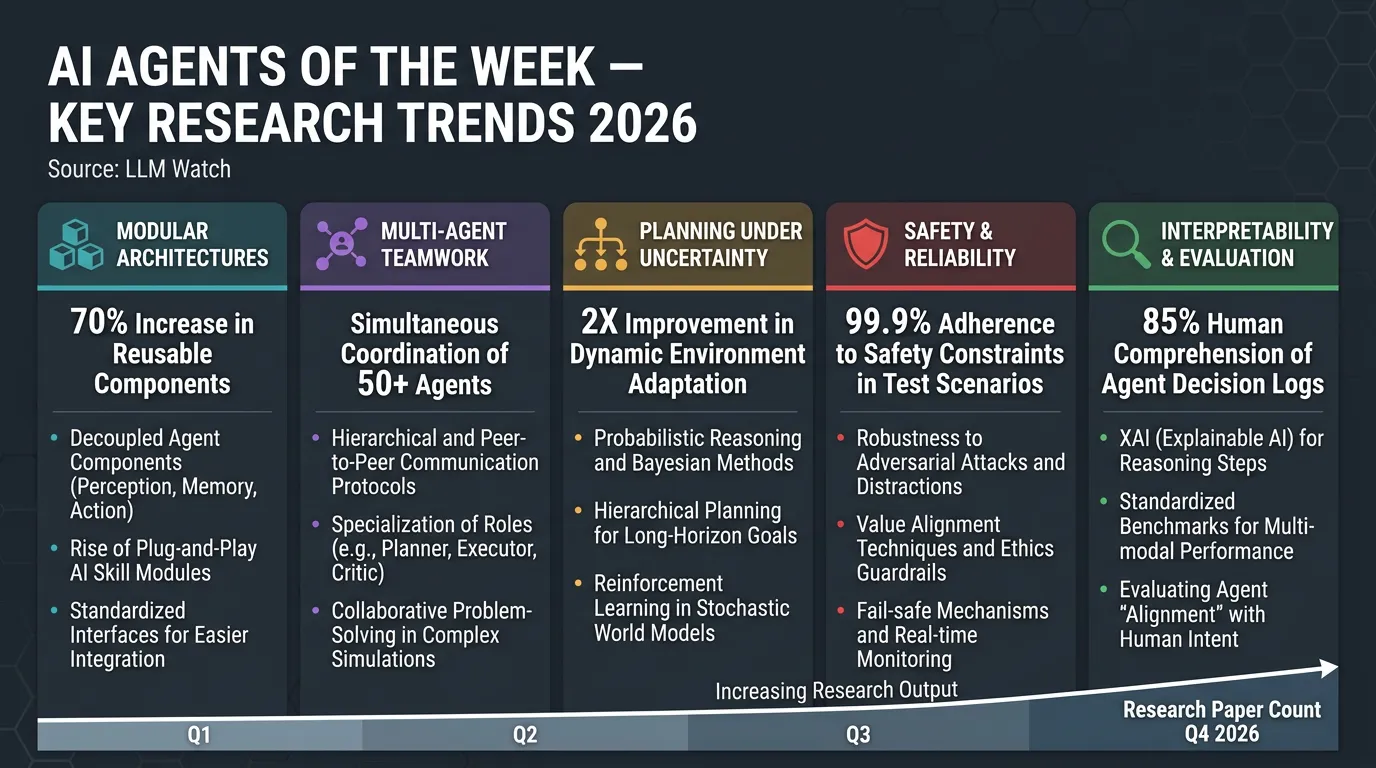
1. 🏗️ Modular, Hierarchical & Self-Improving Architectures
- S1-NexusAgent uses a dual-loop design separating global planning from tool-based subtasks, with a “Critic” module that distills successful trajectories into reusable skills.
- MARS (Modular Agent with Reflective Search) introduces cost-aware planning and reflective memory for expensive AI research workflows.
- Agents break problems into parts, orchestrate specialised modules, and continuously build competencies over time.
2. 🤝 Multi-Agent Systems: Standardisation & Teamwork Pitfalls
- Researchers propose reusable “agent primitives” (e.g. Review, Voting & Selection, Planning & Execution) composable via an organiser agent with shared key-value memory — higher accuracy, lower token cost.
- A separate study found LLM agent teams often underperform their best individual member, with consensus-seeking causing up to 37% performance drops.
- Upside: consensus-driven teams showed unexpected resilience against adversarial members.
- Takeaway: AI collaboration needs new mechanisms to leverage expert agents without groupthink.
3. 🧭 Planning Under Uncertainty: World Models & Assumption Handling
- Planner-Composer-Evaluator (PCE) framework converts implicit LLM assumptions into an explicit decision tree, scoring scenarios by likelihood and cost — outperforming dialogue-heavy baselines with far less communication.
- Reinforcement World Model Learning (RWML) gives agents an internal world model, aligning imagined next states with actual outcomes — significant task success boosts even without direct reward feedback.
- Trend: agents are shifting toward “thinking before acting” — simulating outcomes before committing to actions.
4. 🛡️ Safety & Reliability at the Trajectory Level
- AgentHeLLM threat-modeling framework maps “Agent-to-Agent” attack pathways (e.g. in AI vehicle copilots), separating what needs protection from how attacks occur.
- A conceptual study argues existing uncertainty quantification methods (designed for single-turn QA) break down for sequential agent decisions.
- Proposed reframe: agent confidence as conditionally reducible uncertainty — agents should actively gather information to reduce what they don’t know, rather than uncertainty only accumulating.
- Future designs will integrate explicit uncertainty modeling and threat assessment into decision loops.
5. 🔍 Interpretability & Evaluation Catching Up
- A data-centric interpretability paper used sparse autoencoders + LLM summarisers to analyse multi-agent training logs, uncovering emergent behaviours (role-playing, language switching) and a hidden reward-hacking strategy missed by standard metrics.
- Incorporating discovered insights via a refined prompt boosted agent performance by 14%.
- Growing call for unified evaluation frameworks — current benchmarks vary wildly due to inconsistent prompts, tools, and environments.
Practical Takeaways
- Builders: Adopt modular agent architectures with skill reuse and reflective memory to handle complex tasks more efficiently.
- Teams deploying multi-agent systems: Don’t assume collaboration = better performance. Design explicit mechanisms for expert agents to lead rather than average out.
- Safety teams: Move beyond output-level checks — model threats at the trajectory level and build agents that know their own uncertainty.
- Researchers & evaluators: Invest in interpretability tooling and standardised benchmarks now, before autonomous agents are deployed at scale.
- Everyone: The “safety net” (monitoring, interpretability, evaluation) must grow alongside agent capabilities — capability without accountability is a risk multiplier.