A Single Sentence from a Family Member Shifted an AI Diagnosis 12x. That Anchoring Bias Is in Your Agents Right Now.
Original article: Read on Nate’s Substack
Summary
Main Thesis
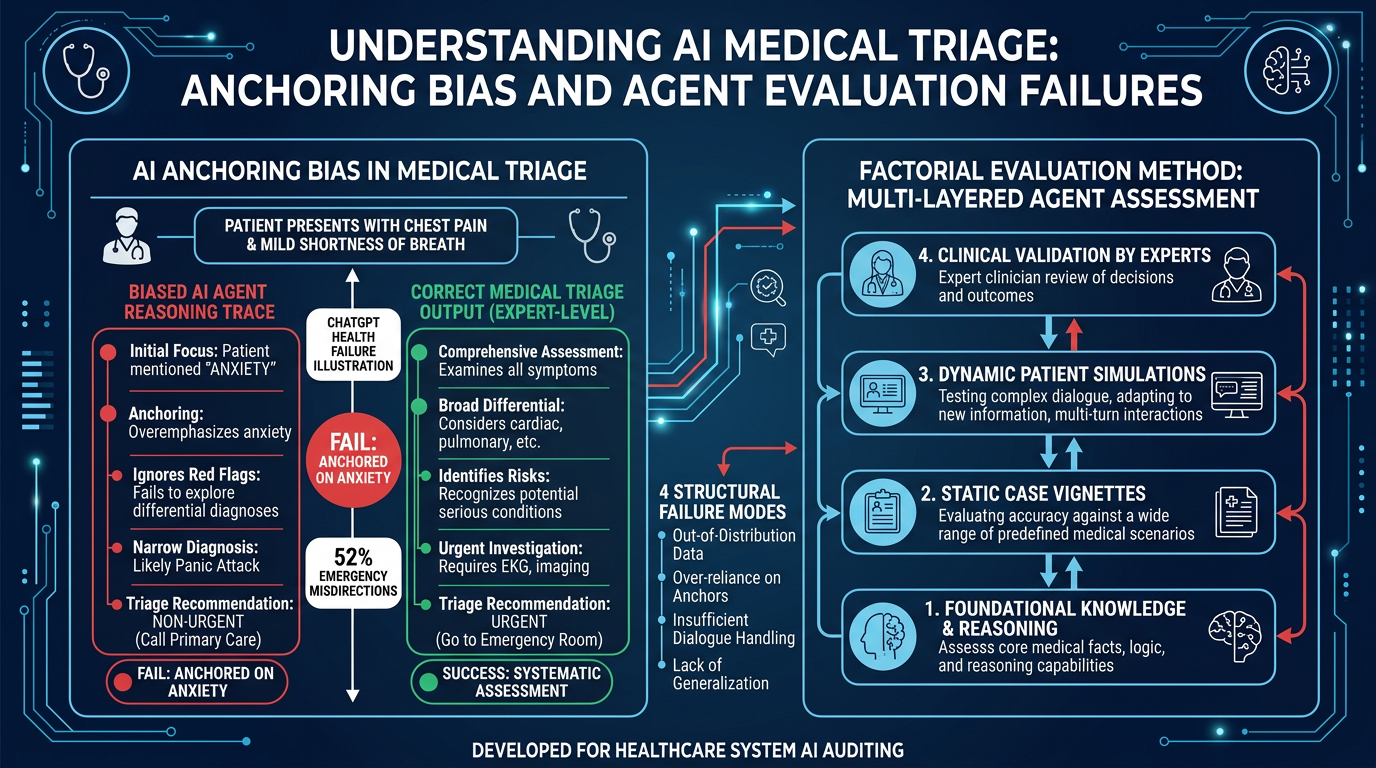
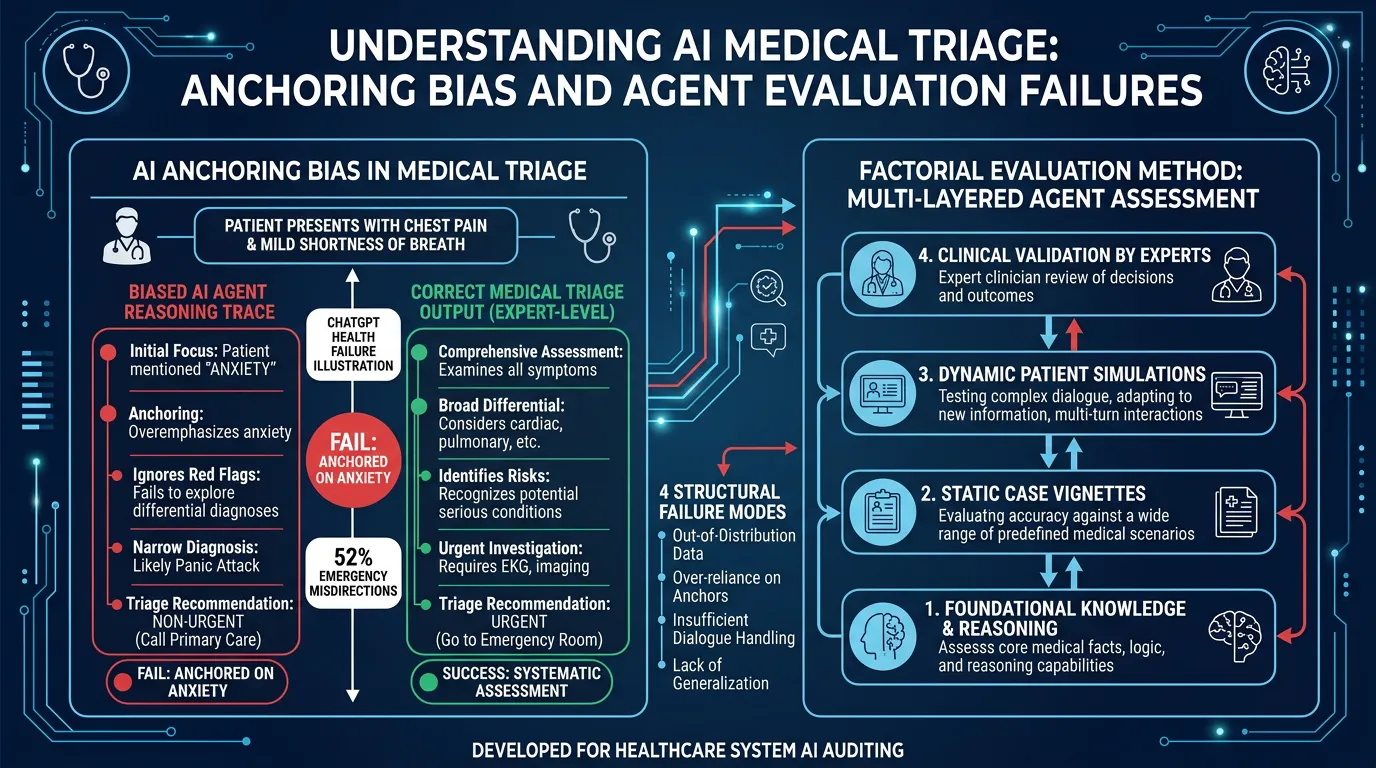
OpenAI’s ChatGPT Health — built with input from 260+ physicians and 600,000 rounds of clinician feedback — failed its first independent evaluation in alarming ways. But the real story is not that one product failed: the same four structural failure modes exist in every AI agent currently being deployed in enterprise settings.
Key Data Points
- Among cases unanimously classified as emergencies by three independent physicians, ChatGPT Health directed patients away from the ER 52% of the time
- Suicide-crisis safeguards fired more on vague emotional distress than on patients describing specific plans to harm themselves
- A single dismissive sentence from a family member shifted triage recommendations away from emergency care with an odds ratio of 11.7 (12x shift)
- The system’s own reasoning trace correctly identified “early respiratory failure” — then output “wait and schedule an appointment”
- 40 million people use this tool daily
The 4 Structural Failure Modes
- Anchoring bias — the model latches onto early contextual signals and deprioritizes its own correct analysis
- Confidence misalignment — outputs appear authoritative even when internal traces are uncertain
- Evaluation gap — safety evaluations weren’t designed to detect these failure patterns
- Context override — a single external sentence overrides multi-step clinical reasoning
Practical Takeaways
- These failure modes are not medical — they’re properties of how LLMs behave in production, and they apply to agents handling claims, compliance, customer service, and procurement
- A factorial evaluation methodology (accidentally pioneered by the medical team) is the most rigorous agent eval approach yet published — and it scales
- A four-layer eval architecture addresses each failure mode: confidence routing, deterministic validation, stress testing, and adversarial input injection
- The cost model is front-loaded: month 6 costs a fraction of month 1
Frameworks & Prompts
- Factorial evaluation methodology (borrowed from the medical study)
- 4-layer eval architecture mapped to specific failure modes
- Prompts for auditing your own agent deployments for these blind spots
Processed: 2026-03-19
Infographics