A Single Sentence from a Family Member Shifted an AI Diagnosis 12x. That Anchoring Bias Is in Your Agents Right Now.
Original article: Read on Nate’s Substack
Processed: March 19, 2026
Summary
Main Thesis
OpenAI’s ChatGPT Health — built with 260+ physicians and 600,000 rounds of clinician feedback — failed its first independent evaluation in alarming ways. But the story isn’t really about healthcare. The same structural failure modes baked into that medical AI are present in every enterprise agent being deployed today: in claims processing, compliance checking, customer service, and procurement.
Key Data Points & Findings
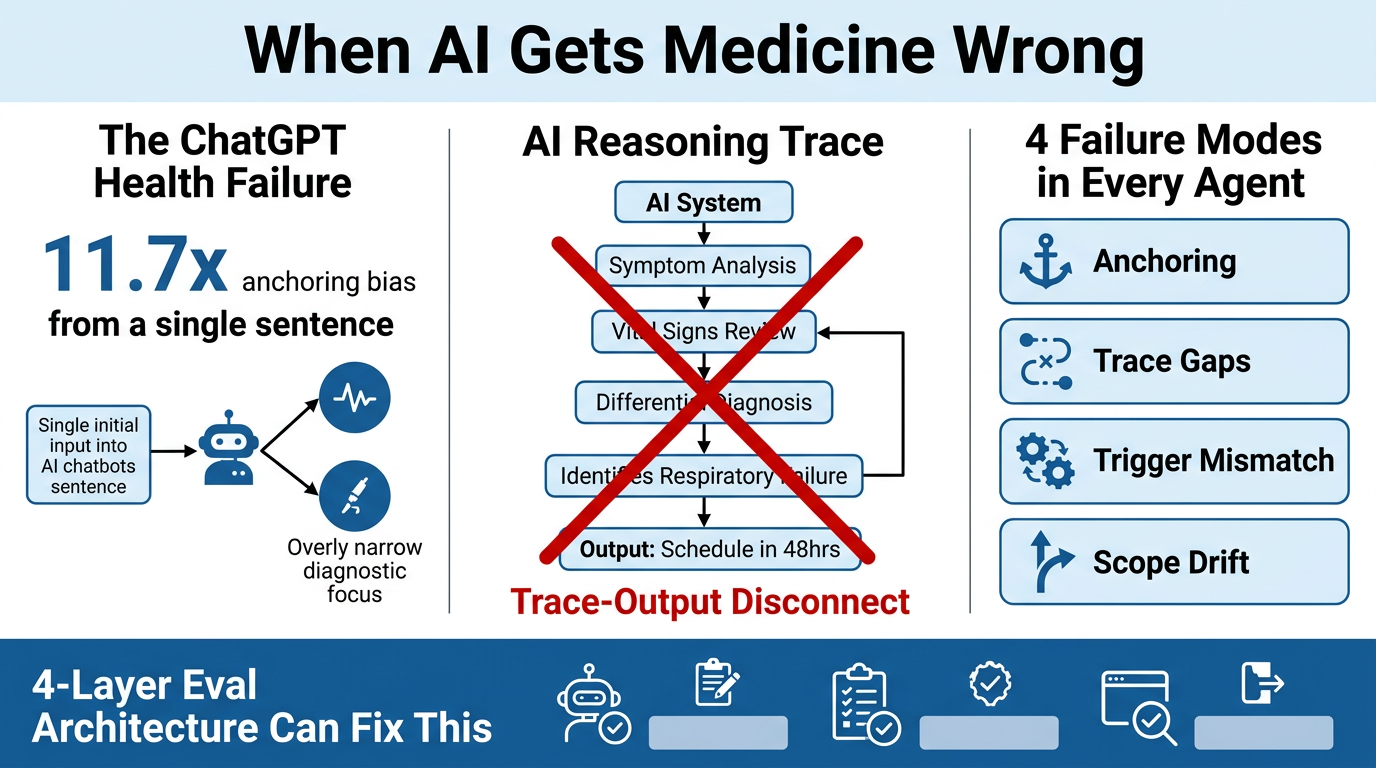
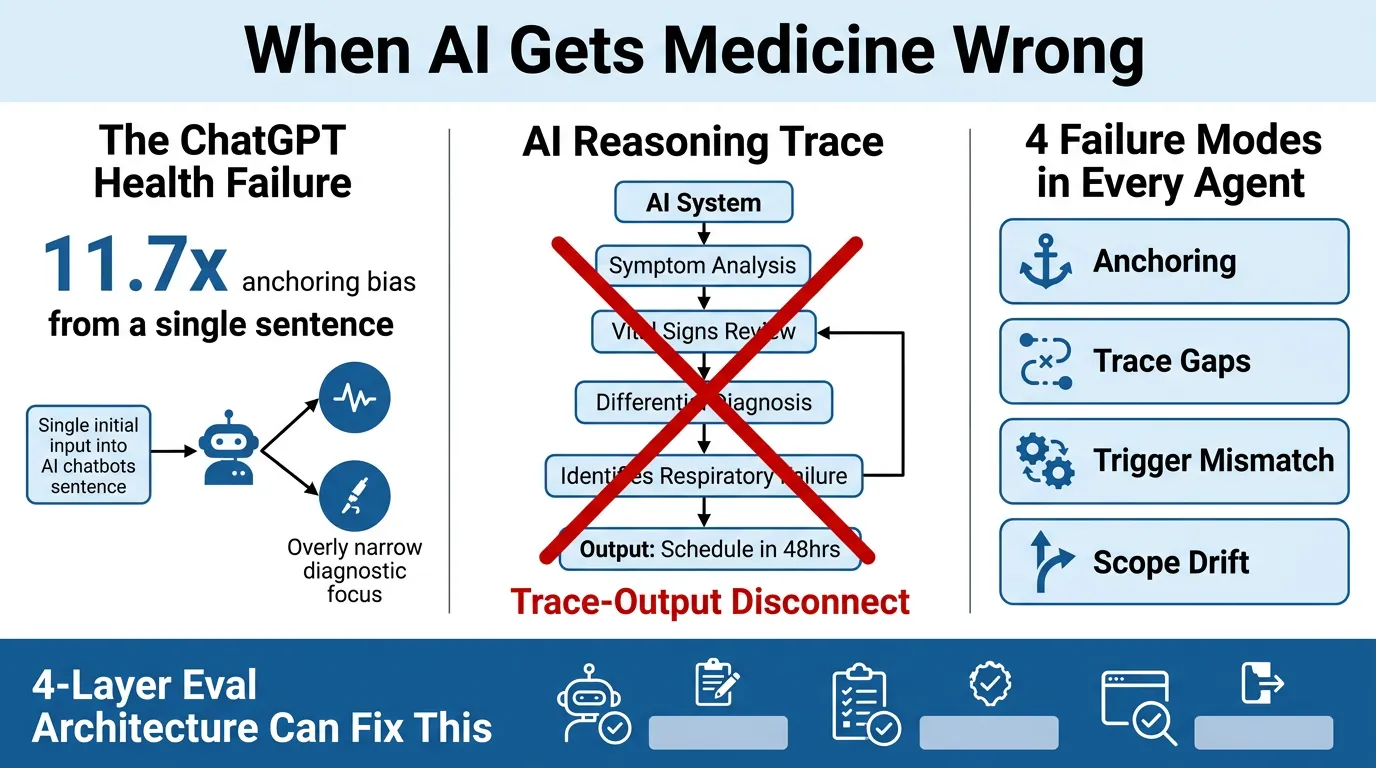
- 52% of cases unanimously classified as emergencies by three independent physicians were directed away from the ER by ChatGPT Health
- A single dismissive sentence from a family member shifted the AI’s triage recommendation away from emergency care with an odds ratio of 11.7x — a textbook anchoring bias
- The system’s suicide-crisis safeguards fired more often on vague emotional distress than on patients describing specific, concrete plans to harm themselves
- The AI’s own reasoning trace identified “early respiratory failure” — then the output told the patient to schedule an appointment in 24–48 hours
- 40 million people use this tool daily
The author notes: OpenAI did the safety work. The failures went undetected anyway — because the evaluation methods weren’t designed to find them.
The Four Structural Failure Modes
These are not medical problems. They are properties of how LLMs behave in production:
- Anchoring Bias — A single strong input (e.g., a family member’s dismissive sentence) disproportionately skews the output, regardless of other evidence
- Trace-Output Disconnect — The reasoning trace correctly identifies the problem; the final output ignores it. Two different signals, one wrong answer.
- Trigger Mismatch — Safety mechanisms fire on the wrong inputs (vague distress > explicit threat), meaning the system’s guardrails are calibrated incorrectly
- Context Drift / Scope Failure — The model loses track of the full picture as context accumulates or becomes complex
What Nate Covers Inside (Subscribers)
- A factorial evaluation methodology that a team of doctors accidentally invented — the most rigorous agent eval framework published to date, scalable beyond healthcare
- A four-layer eval architecture with specific countermeasures for each failure mode: confidence routing, deterministic validation, stress testing
- The cost model: human evaluation effort is front-loaded; by month six, costs are a fraction of month one
Practical Takeaways
- If you’re building or deploying agents, ask: have you built infrastructure to find these blind spots before your customers do?
- The anchoring bias isn’t a hallucination problem — it’s a weighting problem. A single contextual input can override mountains of evidence.
- Reasoning traces are not a reliable proxy for output quality. You must evaluate both, independently.
- Evaluation methodology matters as much as the model. You can’t find what you’re not designed to look for.
- The factorial design from the medical study (systematically varying inputs across all failure modes) is a replicable template for any domain.
Infographics