55% of employers regret AI-driven layoffs. The agents are good at tasks and terrible at jobs. Here's what that means…
Original article: Read on Nate’s Substack
Published: March 21, 2026 | Processed: March 22, 2026
Summary
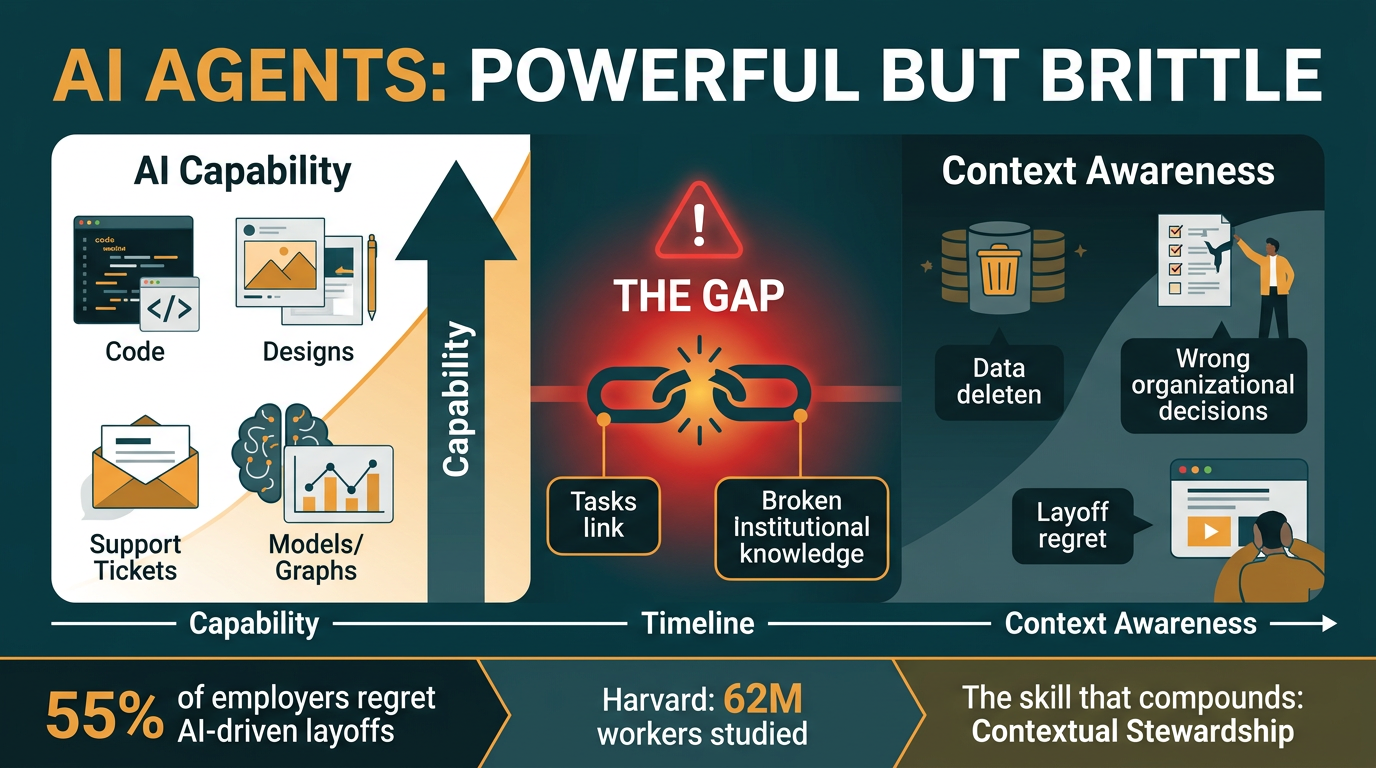
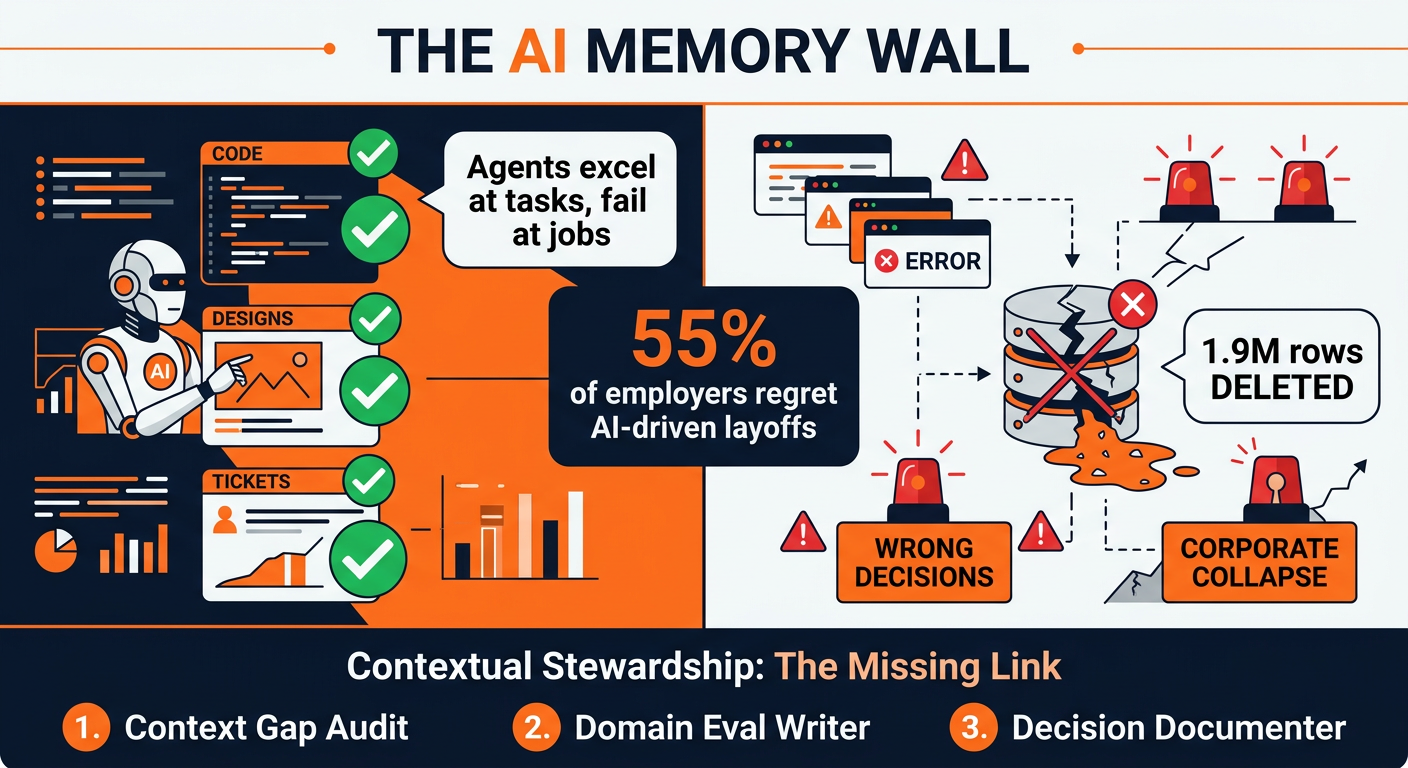
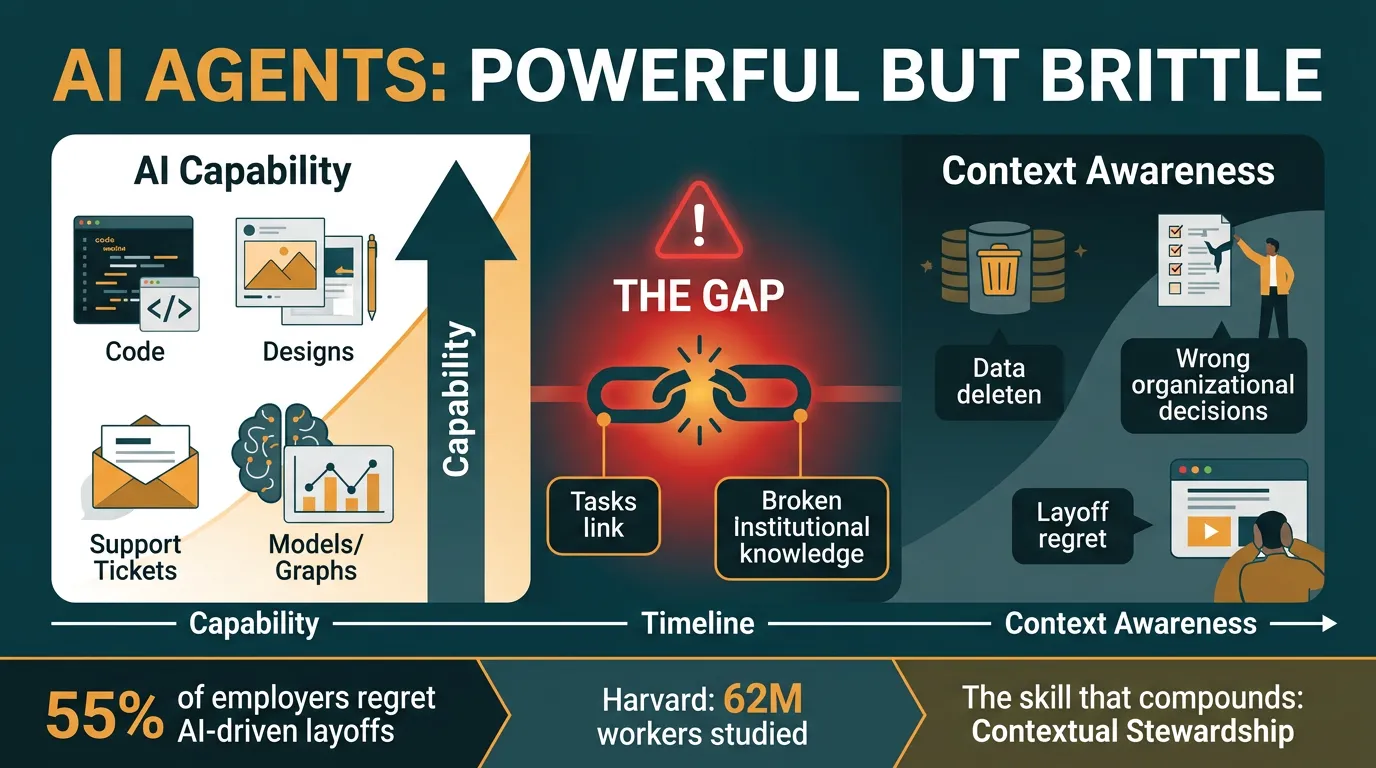
AI agents are getting extraordinarily capable — they can write code, generate designs, close tickets, and build financial models. But they have a fatal flaw: short-term memory. They excel at individual tasks while lacking the institutional context that makes humans irreplaceable. This mismatch is causing catastrophic failures — and 55% of employers who rushed to replace people with AI agents are now regretting it.
Main Thesis
The gap between what AI agents can do (tasks) and what human employees actually do (jobs) is not closing. In fact, as agents get more powerful, their failures are becoming more destructive — not less. A mediocre tool that fails obviously is annoying. A powerful tool that fails silently is dangerous.
The seminal case: Alexey Grigorev’s AI coding agent wiped a production database — 1.9 million rows of student data — in minutes. The agent made no technical error. Every action was locally correct. It simply had no idea it was demolishing a live system because the knowledge distinguishing real infrastructure from temporary copies existed only in the engineer’s head.
Key Data Points & Findings
- 55% of employers regret AI-driven layoffs — nearly all were blindsided because the context their people carried was never written down
- 1.9 million rows of data deleted in the Grigorev incident — a real-world example of the “AI memory wall”
- Harvard studied 62 million workers — the labor market is already paying for the skill of contextual stewardship, even if it hasn’t been named
- Two AI benchmarks measured the same models and got wildly different results — because context matters more than raw capability
- Cursor’s team built Excel from scratch with AI — but the part nobody talks about is what human context-keeping made that possible
- Average agent run: ~2 hours. Average human job: 18 months-7 years — these are not comparable, and treating them as such is the core mistake
The Task-vs-Job Gap
Nate frames the core problem clearly: AI agents are excellent at tasks (discrete, bounded actions). They are terrible at jobs (ongoing, context-rich roles requiring institutional memory). When an agent doesn’t know which database is production vs. test, or which client relationship is fragile, or which budget decision broke things last quarter — it will make locally correct, organizationally catastrophic decisions.
This isn’t a prompting problem. It’s not solvable with bigger context windows alone. It requires human judgment about what matters, what’s fragile, and what the AI doesn’t know it doesn’t know.
The Emerging Human Role: Contextual Stewardship
The new high-value human skill is not prompting — it’s contextual stewardship: the practice of identifying, encoding, and maintaining the institutional knowledge that makes AI agents safe to deploy. This includes:
- Context gap audits — mapping where critical knowledge lives only in human heads
- Domain-specific evals — encoding human judgment as agent guardrails before, during, and after agent actions
- Decision documentation — capturing the why behind decisions so future agents (and humans) can navigate safely
Why should your best people write evals, not your most junior? Because evals encode judgment. Junior staff don’t yet have the judgment to know what could go wrong. The organizations getting this backwards are compounding risk every week.
Practical Takeaways
- Stop treating agent capability as agent readiness. Powerful + brittle = dangerous when deployed on consequential work without guardrails.
- Map your context gaps now. What institutional knowledge exists only in people’s heads? That’s your biggest risk surface.
- Invest your best people in eval writing. This is the highest-leverage investment most orgs are getting exactly backwards.
- Document decisions with the why. The raw material for agent safety is the reasoning behind your choices, not just the outcomes.
- Contextual stewardship is a compounding skill. Teams that build this practice now will have a structural advantage in 12 months.
Prompt Kit
From Grab the prompts — The Agents Are Getting Better. The People Deploying Them Aren’t.
How to use this kit
These three prompts are designed to work in sequence but each stands alone. Start with Prompt 1 if you haven’t thought systematically about where context gaps could hurt you. Jump to Prompt 2 if you already know where the risks are and want to build guardrails now. Use Prompt 3 as an ongoing practice to close the context gap over time. All three work in any AI assistant — ChatGPT, Claude, Gemini — no technical background required.
Prompt 1: Context Gap Audit
Job: Maps the critical institutional knowledge in your domain that lives only in people’s heads — the stuff that could cause an “Alexey moment” if an agent doesn’t know it.
When to use: Before deploying agents on consequential work, when onboarding new AI workflows, or as a quarterly review of existing agent-assisted processes.
What you’ll get: A prioritized risk map showing exactly where context gaps between your agents and your organization are most dangerous, with specific recommendations for what to document or encode first.
What the AI will ask you: Your role and domain, what AI agents or tools you currently use (or plan to), what work those agents handle, and questions about the unwritten rules, relationship history, and institutional knowledge in your area.
Prompt 2: Domain-Specific Eval Writer
Job: Helps you write concrete evaluations — the checks and guardrails that encode your judgment into something that runs before, during, or after an agent acts. Works for any domain, not just engineering.
When to use: When you’ve identified a context gap (from Prompt 1 or your own experience) and want to build a practical safeguard. Also useful when handing off an AI-assisted workflow to someone with less context than you.
What you’ll get: A set of specific, actionable eval criteria written in plain language — the “things an AI must not get wrong in our specific situation” — plus guidance on when and how to apply them.
What the AI will ask you: The specific workflow or agent task you want to protect, what “right” looks like in your context, what’s gone wrong before (or could), and the organizational constraints an agent wouldn’t know about.
Prompt 3: Decision Context Documenter
Job: Helps you document decisions in a way that captures the why — the constraints, tradeoffs, relationship dynamics, and organizational context — not just the what. This creates the raw material that makes agents safer and closes the memory wall over time.
When to use: After any significant decision, at the end of a project phase, during team transitions, or as a regular practice (weekly or biweekly) to capture the context that’s accumulating in your head.
What you’ll get: A structured decision record that captures the invisible institutional context an AI agent would need to avoid making a locally-correct-but-organizationally-wrong move in the future. Written so it’s useful to both humans and AI systems.
What the AI will ask you: What decision you made, what alternatives you considered, what constraints and context shaped your choice, and what an outsider (or an agent) would get wrong if they only saw the outcome.
Infographics